lsdyna_command = f’/software/rapids/r24.04/impi/2021.10.0-intel-compilers-2023.2.1/mpi/2021.10.0/bin/mpirun -genv I_MPI_PIN_DOMAIN=core -np 147 /software/rapids/r24.04/LS-DYNA/14.1.0-intel-2023b/ls-dyna_mpp_d_R14_1_0_x64_centos79_ifort190_avx2_intelmpi-2018_sharelib i={new_file_path} memory=128M'
run_command(lsdyna_command)
For the above, the simulation started execution but appears to be terminated before total completion time. In my d3hsp, it gave out
709 t 3.5450E-05 dt 5.00E-08 electromagnetism step
License routines forcing premature code termination.
Contact with the license server has been lost.
The server may have died or a network connectivity problem
may have occurred.
710 t 3.5500E-05 dt 1.00E+06 write d3dump01 file 12/24/24 21:37:58
710 t 3.5500E-05 dt 1.00E+06 flush i/o buffers 12/24/24 21:37:58
710 t 3.5500E-05 dt 1.00E+06 write d3plot file 12/24/24 21:37:59
N o r m a l t e r m i n a t i o n 12/24/24 21:37:59
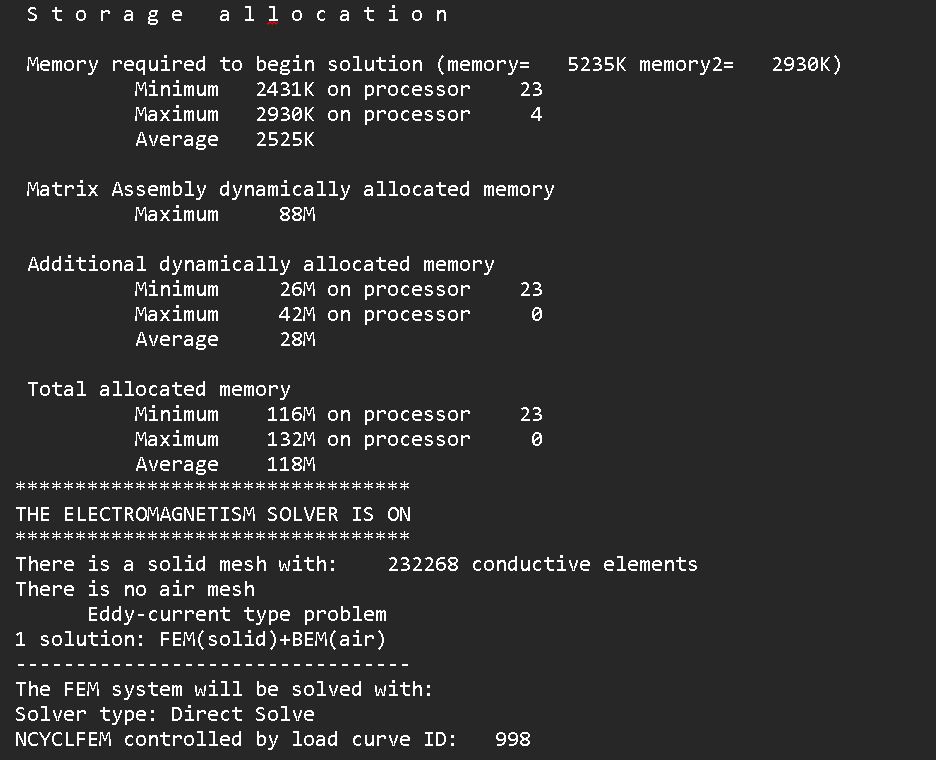
S t o r a g e a l l o c a t i o n
Memory required to complete solution (memory= 5235K memory2= 2508K)
Minimum 2408K on processor 5
Maximum 2508K on processor 36
Average 2424K
Matrix Assembly dynamically allocated memory
Maximum 56M
Additional dynamically allocated memory
Minimum 162M on processor 121
Maximum 217M on processor 146
Average 170M
Total allocated memory
Minimum 220M on processor 121
Maximum 275M on processor 146
Average 228M
T i m i n g i n f o r m a t i o n
CPU(seconds) %CPU Clock(seconds) %Clock
—————————————————————-
Keyword Processing … 2.8257E+00 0.01 2.8348E+00 0.01
MPP Decomposition …. 1.6675E+01 0.06 1.7915E+01 0.06
Init Proc ………. 1.0730E+01 0.04 1.0759E+01 0.04
Decomposition …… 5.4681E-01 0.00 5.5070E-01 0.00
Translation …….. 5.3983E+00 0.02 6.6042E+00 0.02
Initialization ……. 1.3516E+01 0.05 1.3698E+01 0.05
Init Proc Phase 1 .. 2.6186E+00 0.01 2.6754E+00 0.01
Init Proc Phase 2 .. 1.4131E+00 0.01 1.4373E+00 0.01
Element processing … 9.0849E-01 0.00 6.1107E+01 0.22
Solids …………. 5.8148E-01 0.00 3.8135E+01 0.13
E Other ………… 8.5733E-02 0.00 6.8885E+00 0.02
Binary databases ….. 2.9037E+01 0.10 4.4529E+01 0.16
ASCII database ……. 1.1411E-01 0.00 7.0965E+00 0.03
Contact algorithm …. 8.2748E+01 0.30 1.1298E+02 0.40
Interf. ID 1 1.9341E+01 0.07 1.9670E+01 0.07
Interf. ID 2 5.4628E+01 0.20 7.0596E+01 0.25
Rigid Bodies ……… 4.2108E+01 0.15 5.3479E+01 0.19
EM solver ………… 2.7242E+04 98.45 2.7758E+04 97.85
Misc …………… 6.1301E+02 2.22 6.6360E+02 2.34
System Solve ……. 2.5164E+04 90.94 2.5492E+04 89.86
FEM matrices setup . 1.1896E+02 0.43 1.3114E+02 0.46
BEM matrices setup . 3.5966E+02 1.30 3.8563E+02 1.36
FEMSTER to DYNA …. 4.3925E+02 1.59 5.2618E+02 1.85
Compute fields ….. 5.4711E+02 1.98 5.5925E+02 1.97
Time step size ……. 1.4727E+02 0.53 1.5686E+02 0.55
Group force file ….. 1.0339E-02 0.00 8.1230E-01 0.00
Others …………… 1.1413E+01 0.04 1.6252E+01 0.06
Force Sharing …… 1.1304E+01 0.04 1.3013E+01 0.05
Misc. 1 ………….. 4.3898E+00 0.02 2.2644E+01 0.08
Scale Masses ……. 7.7710E-03 0.00 5.5401E-01 0.00
Force Constraints .. 1.3901E-02 0.00 6.8301E-01 0.00
Force to Accel ….. 1.0230E-02 0.00 7.7030E-01 0.00
Constraint Sharing . 3.3435E-02 0.00 1.2809E+00 0.00
Update RB nodes …. 3.8281E-02 0.00 2.4141E+00 0.01
Misc. 2 ………….. 1.1875E-01 0.00 9.0182E+00 0.03
Misc. 3 ………….. 7.7356E+01 0.28 8.4258E+01 0.30
Misc. 4 ………….. 1.1225E-01 0.00 6.7043E+00 0.02
Timestep Init …… 1.6812E-02 0.00 4.6854E-01 0.00
Apply Loads …….. 8.1626E-02 0.00 5.6807E+00 0.02
—————————————————————-
T o t a l s 2.7670E+04 100.00 2.8368E+04 100.00
Problem time = 3.5500E-05
Problem cycle = 710
Total CPU time = 27670 seconds ( 7 hours 41 minutes 10 seconds)
CPU time per zone cycle = 161549.932 nanoseconds
Clock time per zone cycle= 165622.228 nanoseconds
Parallel execution with 147 MPP proc
NLQ used/max 64/ 64
I think the totoal termination has not executed, it prematurely stopped execution