

Tagged:
-
-
July 11, 2024 at 1:56 pm
 FAQParticipant
FAQParticipant
Last Updated: April/2026
With Ansys Rocky™ particle dynamics simulation software you can use one or more Graphic Processing Units (GPUs) to process your simulations. Before investing in new hardware, see the FAQs below to find guidelines and recommendations.
Mastering Multi-GPU in Ansys Rocky Software and Enhancing Its Performance
/ Rocky GPU Performance Benchmark
- Rocky GPU Performance Benchmark
- The benefits of GPU
- Performance Benchmark
- Benchmark results for Ansys Rocky 2026 R1
- Relevant conclusions on simulation performance
- Rocky GPU Performance Benchmark – DEM case (Distributed parallel computing)
- Rocky GPU Performance Benchmark – CFD-DEM case
- Rocky GPU Performance Benchmark – SPH case
/ Rocky GPU FAQs
- Which license is required to run Rocky on GPUs?
- Which GPU cards are recommended for use with Rocky?
- What are the minimum requirements for GPU cards that will be used for running Rocky?
- What cards are best for running only spherical particles? What about cases using shaped particles?
- Which cards are best for running SPH?
- Can you provide some examples for comparison?
- There are a lot of cards on that list! How do I choose the one that is right for me?
- I have only a mid-range budget. Can you recommend a card for me?
- If you had to recommend one, all-around best card for most situations, which would it be?
- Won’t the (non-recommended) card I already have work just as well as a recommended one?
- Assuming I use a recommended GPU card, how much faster can I expect my simulations to run?
/ Rocky GPU FAQs
/1. Which license is required to run Rocky on GPUs?
The Ansys Rocky base product license allows you to run a single job with up to 112 graphic cards SM’s (Streaming Multiprocessor). It is indifferent whether this is with a single or multiple GPU cards.
For example, if you have one A100 card (108 SMs), you can run your Rocky simulation without needing any additional HPC license. In the same way, if you have four RTX 3060 cards (28 SM’s each), you can run on multi-GPU as the total SM’s count in this case is 112.*
To run any job with more than 112 SM’s, you need to add Ansys Rocky HPC Licensing. 1 Ansys Rocky HPC task enables 14 SM’s, e.g, 1 Ansys Rocky HPC-8 license includes 8 tasks, that enables 112 additional SM’s.
Additional SM’s can be enabled with Ansys Rocky HPC Licensing.
1 Ansys Rocky HPC task enables 14 SM’s, e.g, 1 Ansys Rocky HPC-8 license includes 8 tasks, that enables 112 additional SM’s.
SM’s
Rocky HPC tasks
1 – 112 0 113 – 224 1 – 8 225 – 336 9 – 16 337 – 560 17 – 32 561 – 1008 33 – 64 Now consider another situation, in which you have one RTX 4090 card (128 SM’s) or five RTX 3060 cards (140 SM’s). In both cases you will need to invest in 1 Rocky HPC-8 License (see the table below).
HPC features required according to the card(s) SM count
RTX 3060 RTX 4090 Cards SM Count Rocky HPC-8 Cards SM Count Rocky HPC-8 1 28 0 1 128 1 2 56 0 2 256 2 3 84 0 3 384 3 4 112 0 4 512 4 5 140 1 5 640 5 6 168 1 6 768 6 *For more information about SMs, refer to the APPENDIX section.
Notes:
- When using multiple GPU’s, licensing is based on the total number of SM’s across all GPU’s irrespective of the number of GPU’s.
- All available SM’s are used on a GPU card. It is not possible to restrict usage to a subset of SM’s.
- Since 2026 R1 Rocky has support for GPU distributed computing (only for sphere particles with no coupling and Linux-only). However, this is a Beta feature and work is ongoing.
- We advise that all GPU cards reside on a single server, because Ansys Rocky does not fully support distributed GPU computing.
/2. Which GPU cards are recommended for use with Rocky?
Rocky team considers that the following NVIDIA GPU cards may be interesting for Rocky Solver:
- Server: A30, A100, L40, H100, H100 NVL and H200.
- PROS: Faster when using spherical and/or shaped particles and/or SPH elements
- CONS: More expensive; must be installed on a server rack; no video output
- Workstation: Quadro RTX A6000, RTX A2000, RTX A4000, RTX A5000
- PROS: Faster when using only spherical particles and/or SPH elements; can be installed on individual workstations; has video output
- CONS: Cost is still high expensive
- Gaming: RTX 3060, RTX 3070, RTX 4060, RTX 4090 and RTX5060
- PROS: Faster when using only spherical particles and/or SPH elements; inexpensive; can be installed on individual workstations; has video output
- CONS: Slower when using shaped particles
For better results, use only the above recommended GPU cards during Rocky processing.
Gaming cards can have good performance when running small cases with spherical particles and/or SPH elements but may not be the best choice for simulations with shaped particles.
/3. What are the minimum requirements for GPU cards that will be used for running Rocky?
There are some minimum requirements for GPU or multi-GPU processing, and you must choose one or more NVIDIA GPU cards (computing or gaming), according to the following criteria:
At least 4 GB memory.
Fast double-precision processing capabilities.
A CUDA compute capability of 6.0 or higher.
A graphics driver version that supports the CUDA version 12.8 toolkit or higher.
(Access Nvidia website to see a CUDA driver table with a list of which driver version supports which toolkit version)
/4. What cards are best for running only spherical particles? What about cases using shaped particles?
Regarding particle shapes, here are some guidelines:
When running cases with shaped particles, choosing GPUs with higher double-precision performance should be your primary focus.
When running cases using only spherical particles, choosing GPUs with higher memory bandwidth will get you faster results in your processing.
If you intend to run very large cases, with millions of particles, you should consider GPUs with larger memory size.
Consider cards that have poor double precision, but considerable memory bandwidth performance. This means that they will perform very well when simulating only spherical particles, but very poorly with shaped particles. This is a critical point when you are deciding which card to purchase.
/5. Which cards are best for running SPH?
For simulation with only SPH elements, choose a GPU with high single-precision performance and higher memory bandwidth so you will speed up your simulations. GPUs with larger memory allow you to run bigger cases with millions of SPH elements, so keep it in mind when selecting the hardware.
If you are going to run simulations with both SPH elements and DEM particles together, you must take the tips from the last section into account, since the performance bottleneck can be either the SPH or the DEM, depending on the element/particle amount and the particle shape.
/6. Can you provide some examples for comparison?
The table below show that the RTX 5060 Ti is about than 23% faster than the RTX 5060 attributed to its higher double-precision, with the Ti model having two times memory. If you look compare H100 and H100 NVL you can have almost two times more memory bandwidth buying the NVL version with just 20% more investment. Also, you can get almost 20% more double precision (Gflops) using the NVL version.
Comparing the cards RTX 3090 with the RTX 3090 Ti, both have the same memory size, and the Ti version is 12% faster. Despite the performance gain not being too substantial, probably, the cost is not significant and in this case the Ti version would be a better choice. Meanwhile, if the performance is a bottle neck, the RTX 4090 could be considered as an option, as it is 2x faster than the RTX 3090 with the same memory size. In this case, an assessment of the pros and cons is required, as the RTX 4090 has a higher cost and requires a HPC license due to its SM count.
/7. There are a lot of cards on that list! How do I choose the one that is right for me?
Choosing the card that will work best for you depends upon the type of simulations you will be running, how fast you need those simulations to complete, and the budget available to spend on your hardware.
The below tables provide a quick comparison of the most common workstation, server and gaming cards.
*Last update March 2026. Prices are estimated and can vary from region to region, market demand and other reasons.
Card Name Memory Size (GB) Memory Bandwidth (GB/s) SMs Single Precision (Tflops) Double Precision (Gflops) Estimated Purchase Price* (USD) Workstation Cards RTX A6000 48 768 84 38.71 605 4,600 – 5,200 RTX 6000 Ada 48 960 142 91 1423 6,800 – 7,500 RTX A2000 12 288 26 7.9 124.8 450 – 600 RTX A4000 16 448 48 19.2 299.5 800 – 1,100 RTX A5000 24 768 64 27.8 433.9 2,200 – 2,500 RTX PRO 2000 16 288 34 17.03 266.2 800 – 840 RTX PRO 4000 24 432 70 24.05 375.8 1700 – 2000 Server Cards A30 24 930 56 10.3 5161 3,500 – 5,000 A100 40 1555 108 19.5 9746 8,000 – 11,000 A100 80GB 80 1935 108 19.5 9746 12,000 – 17,000 H100 80 2039 114 51.22 25610 25,000 – 32,000 H100 NVL 94 3940 132 60.32 30160 30,000 – 38,000 L40 48 864 142 90.52 1414 9,500 – 11,000 H200 141 4800 132 60.32 30160 31,000 – 42,000 Gaming Cards RTX 3060 Ti 8 448 38 16.2 253.1 250 – 300 (Used) RTX 3070 8 448 46 20.31 317.4 300 – 400 (Used) RTX 3070 Ti 8 608.3 48 21.75 339.8 300 – 400 (Used) RTX 3080 10 760 68 29.77 465.1 450 – 600 (Used) RTX 3080 Ti 12 912.4 80 34.1 532.8 450 – 600 (Used) RTX 3090 24 936.2 82 35.58 556 700 – 900 (Used) RTX 3090 Ti 24 1008 84 40 625 700 – 900 (Used) RTX 4090 24 1008 128 82.58 1290 1,600 – 1,900 RTX 5060 8 448 30 19.18 299.6 320 – 380 RTX 5060 Ti 16 448 36 23.7 370.4 450 – 550 RTX 5090 32 233.75 170 104.8 1637 1,999 – 2,500 /8. I have only a mid-range budget. Can you recommend a card for me?
On the mid-price range of cards, there are the two generations of RTX’s workstation cards: A6000 and A6000 Ada. Both have same memory size (48 GB) and poor double precision compared to server cards. In the other hand, the card A30 has half memory (24 GB) but blazing-fast double precision. A good option for a mid-range budget could be the A100, which performs highly in double precision, has good memory (40 GB) and has great memory bandwidth (1555 GB/s).
Thus, you need to choose what you need: larger memory (better for running larger cases with only spherical particles or with SPH elements) or faster double precision (better for running cases with shaped particles).
Another interesting GPU card to look at is the L40 (good memory and double precision). Its cost is higher than A6000, however the performance could compensate the extra investment.
/9. If you had to recommend one, all-around best card for most situations, which would it be?
All in all, the A100 is by far the Rocky team’s preferred choice. It has a good amount of memory, blazing-fast double precision, and it delivers the most in terms of processing capacity given its cost.
And if it turns out your simulation does not fit onto a single GPU, you can always use Rocky’s support for multi-GPU to stack-up the GPU’s combined memory.
/10. Won’t the (non-recommended) card I already have work just as well as a recommended one?
Different GPU cards can have one order of magnitude difference in performance, which is why we have recommended only the cards that will have the best performance with Rocky. Just because Rocky appears to run fine on a non-recommended GPU card, does not mean that it is helping the processing performance. And if it is not helping the performance, then there is no point in running your simulations on GPUs.
To see for yourself the huge range of performance differences, visit the Nvidia and review the Processing Power / Single Precision / Double Precision of the GPUs cards.
/11. Assuming I use a recommended GPU card, how much faster can I expect my simulations to run?
Compared to a CPU with 8 cores, adding even one GTX 980 has been shown to speed up the processing time 5 fold; add in three P100s and what was once a 3-day simulation can be completed in just over an hour. But it all depends upon what you are simulating, how large your case is, and how much budget you have.
Appendix: What are Streaming Multiprocessors (SMs)?
Streaming Multiprocessors (SMs) are key components of the NVIDIA GPU’s responsible for executing parallel computations, perform tasks related to rendering and other general-purpose computing. A SM consists of multiple CUDA cores and more powerful GPU cards typically contain more SM’s.

GH100 Full GPU architecture with 144 SMs
/Rocky GPU Performance Benchmark
In the past, DEM simulations were restricted to relatively small problems that used, for example, only thousands of larger particles that were mostly spherical in shape.
Continual improvements in both DEM codes and computational power have enabled closer-to-reality particle simulations. Users today can expect to simulate problems using the real particle shape and the actual particle size distribution (PSD), creating DEM simulations with many millions of particles.
However, these enhancements in simulation accuracy have come at the cost of increased computational loads in both processing time and memory requirements. Within Rocky, these loads can be offset considerably by using GPU processing abilities, which provides users with the capacity to obtain results in a more practical time frame.
The benefits of GPU
The addition of GPU processing has helped to make DEM a practical tool for engineering design. For example, the speed-up experienced by processing a simulation with even an inexpensive gaming GPU is remarkable when compared to a standard 32-core CPU machine working alone.
Since the release 4 of Rocky, users have been able to make use of multi-GPU technology capabilities, which facilitates large-scale and/or complicated solutions that were previously impossible to tackle due to memory limitations. By combining the memory of multiple GPU cards at once, users have been able to overcome these limitations and achieve a substantial performance increase by aggregating their computing power.
From an investment perspective, there are many benefits to multi-GPU processing. The hardware cost of running cases with several millions of particles using multiple GPUs is much smaller than buying an equivalent CPU-based machine. The energy consumption is also less with GPUs, and GPU-based machines are also easier to upgrade by adding more cards or buying newer ones.
Moreover, in a world where we push multi-physics simulations ever farther, Rocky GPU and multi-GPU processing enables you to free-up all your CPUs for coupled simulations, avoiding hardware competition.
Performance Benchmark
To better illustrate the gains in processing speed that are possible for common applications, a performance benchmark of a rotating drum (Figure 1) was developed. Multiple runs using different criteria were evaluated as explained below.

Figure 1 – Rotating drum benchmark case.
Criteria 1: Particle shape
Two different particle shapes were evaluated at the same equivalent size (Figure 2):
- Spheres
- Polyhedrons (shaped from 16 triangles)
Drum geometry was lengthened as the number of particles increased to keep the material cross-section consistent across the various runs.
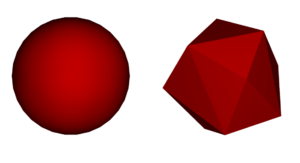
Figure 2 – Sphere (left) and 16-triangle polyhedron (right) particle shapes used in the benchmark case.
Criteria 2: Processing type
Four different processing combinations were evaluated:
- CPU: Intel(R) Xeon(R) Gold 6542Y @ 2.90 GHz on 48 cores
- 1 GPU: NVIDIA H100, NVIDIA A100, NVIDIA L40
- 2 GPUs: NVIDIA H100, NVIDIA A100, NVIDIA L40
- 4 GPUs: NVIDIA L40
Criteria 3: Performance measurement
Two measurements were taken at steady state to evaluate performance:
- Simulation Pace (speed up), which is the amount of hardware processing time (duration) required to advance the simulation one second. In general, a lower simulation pace indicates faster processing. The simulation speed up metric is used considering the CPU pace as reference.
- GPU Memory Usage, which is the amount of memory being used on the GPU while processing the simulation. In general, a lower memory usage allows for more particles to be processed, and/or more calculations to be performed.
Benchmark results for Ansys Rocky 2026 R1
GPUs Tested in Ansys Rocky 2026 R1
Relevant conclusions on simulation performance
The following plots, from Figure 3 to Figure 6, show the performance gains for spheres and polyhedrons for different numbers of particles, using different models and numbers of GPU.
- Rocky’s latest CPU simulation enhancements significantly reduced execution times when running on standard processors. Compared to previous releases, the GPU speed-up is lower, but still significantly high.
- The performance gain running in GPU or multi-GPU is significant. You can achieve the same result in a multi-GPU simulation up to 41 times faster than 48-cores CPU. Using one GPU
- Excellent scalability and efficiency were observed for all GPU cards tested.
Figure 3 – GPU speed-up based upon Simulation Pace (compared with CPU 48x cores) achieved using 16 million spheres.
Figure 4 – GPU speed up based upon Simulation Pace (compared with CPU 48x cores) achieved using 32 million spheres.
Figure 5 – GPU speed up based upon Simulation Pace (compared with CPU 48x cores) achieved using 16 million polyhedrons.
Figure 6 – GPU speed up based upon Simulation Pace (compared with CPU 48x cores) achieved using 32 million polyhedrons.
Relevant conclusions on GPU memory consumption
From Figure 7 to Figure 10 the GPUs memory usage is shown for spheres and polyhedrons for different numbers of particles using different models and numbers of GPUs.
- For the case with 26 million sphere particles, simulations takes total memory consumption is, approximately between 23GB and 26GB. For 16 millions polyhedrons the range of GPU memory used is from 43GB to 46GB.
- Considering the simulation with 32 million sphere particles the GPU memory usage is from 47GB to 50GB, approximately. For 32 million polyhedrons the total memory consumption is up to 90GB.
- Ansys Rocky can simulate 32 million polyhedrons using 90GB of GPU memory, in other words this means that 90GB could be used to simulate about 185 million spheres particles.
Figure 7 – Total GPU memory consumption using 16 million spheres.
Figure 8 – Total GPU memory consumption using 32 million spheres.
Figure 9 – Total GPU memory consumption using 16 million polyhedrons.
Figure 10 –Total GPU memory consumption using 32 million polyhedrons.
Rocky GPU Performance Benchmark – DEM case (Distributed parallel computing)
Important: Note that beta features have not been fully tested and validated. Ansys, Inc. makes no commitment to resolve defects reported against these prototype features. However, your feedback will help us improve the overall quality of the product. We will not guarantee that the projects using this beta feature will run successfully when the feature is finally released so you may, therefore, need to modify the projects.
Since Rocky 2026R1 release, it is possible to run Rocky software in multi-node clusters. Currently, there are a series of limitations regarding this Ansys Rocky feature. The two most significants are the particles that you can run and which hardware is possible to use. First, only sphere particles are available to be evaluated. Second, it is only possible to run GPUs only in Linux distros.
Relevant conclusions on simulation performance
Figure 11 and Figure 12 show the speed-up for 16 million and 32 million sphere particles. The results for 4x GPUs and for 6x GPUs are those runned in two and three nodes, respectively.
- For the A100 card the scalability and the efficiency are great. For the H100, results are good, the performance can be improved by simulating a problem with more particles. Then, the solver will utilize more GPU memory and memory bandwidth. In other words, for a 16 million particle simulation, the memory bus in 4 H100, makes the CUDA cores waste too much time to exchange information.
- The speed-up for 32 million sphere particles shows an improvement in H100 efficiency. As stated in the previous item, more particles more GPU memory and more memory bandwidth. As consequence, less memory bus when running simulations with 4 H100, less time to communicate between CUDA cores and efficiency improvement.
Figure 11 – GPU speed-up based upon Simulation Pace (compared with CPU 48x cores) achieved using 16 million spheres.
Figure 12 – GPU speed-up based upon Simulation Pace (compared with CPU 48x cores) achieved using 32 million spheres.
Relevant conclusions on GPU memory consumption
Figure 13 and Figure 14 show the memory consumption for the cases with 16 and 32 million sphere particles.
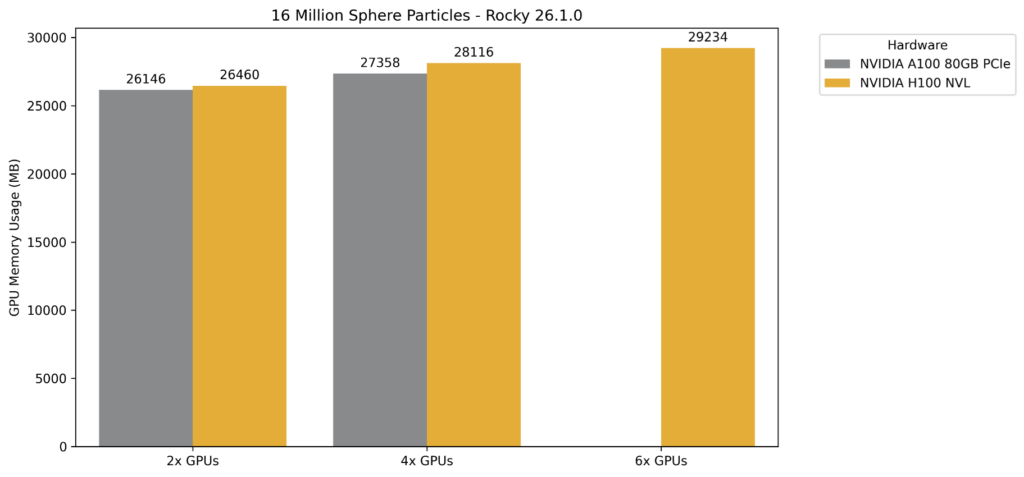
Figure 13 – Total GPU memory consumption using 16 million spheres.
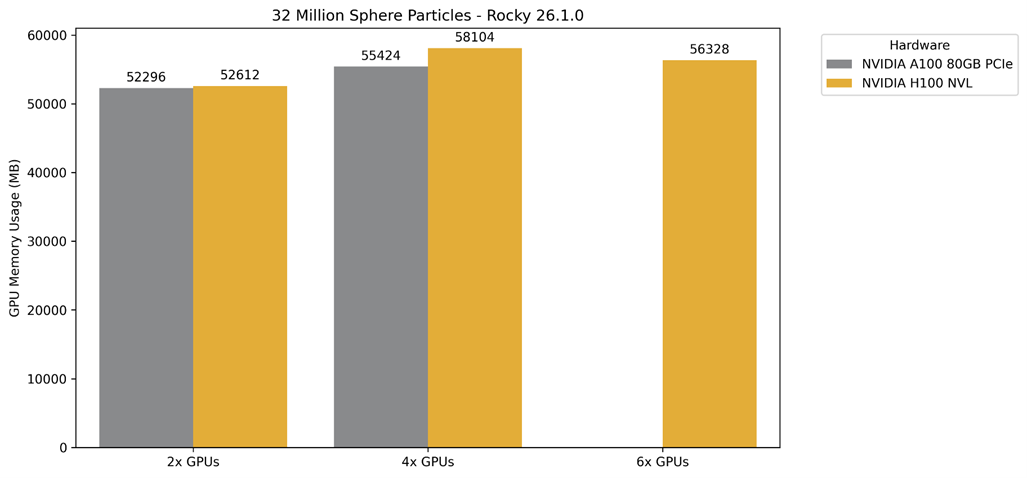
Figure 14 – Total GPU memory consumption using 32 million spheres.
Rocky GPU Performance Benchmark – CFD-DEM case
A coupling between CFD (Computational Fluid Dynamics) and DEM is fundamental computing the discrete phase of systems that mix fluid and granular particles.
For many industrial applications, a CFD-only simulation (often neglects particle-particle interactions) is physically insufficient. This happens because the interaction between particle and particle is not considered. Consequently, this approach is generally restricted to dilute flows. By integrating DEM, we can account for collisions and enduring contacts, allowing for the study of dense-phase flows. In this guide we will explore just the 1-way approach.
The benefits of GPU
To simulate an engineering device through coupling CFD and DEM is one of the most computationally expensive tasks. Many physical problems are unfeasible or extremely expensive to solve using CPU.
Traditionally, solving these systems on CPUs was either cost-prohibitive or too slow for industrial design cycles. Nowadays, thanks to GPU advancements, complex coupling simulations with CFD-DEM solvers are becoming feasible. Consequently, simulation engineers can tackle relevant industrial problems using GPU.
Performance Benchmark
To analyze the performance of the CFD-DEM coupling, a cyclone separator problem was developed, see Figure 15. As stated in the previous section, the coupling evaluated is a 1-way coupling. Here, the Ansys Rocky solver plays a more significant role in overall simulation performance.
Similar to the DEM benchmark, multiple runs were evaluated to gather information to assess Ansys Rocky.

Figure 15 – Cyclone benchmark case.
Criteria 1: Particle details
In the present problem the DEM phase is modeled by spheres particles. The discrete phase has about 185 millions of sphere particles. The size is a Particle Size Distribution as follow:
Diameter (d) Cumulative (%) 5.0 x 10-5m 100% 4.1×10-5m 97.5% 3.2×10-5m 91.75% 2.3×10-5m 77.52% 1.4×10-5m 44.48% 5.0×10-6m 30% Criteria 2: Processing type
Four different processing combinations were evaluated:
- CPU: Intel(R) Xeon(R) Gold 6542Y CPU @ 2.90 GHz on 48 cores
- 1 GPU: NVIDIA H100, NVIDIA A100
- 2 GPUs: NVIDIA H100, NVIDIA A100
- 4 GPUs: NVIDIA L40
Criteria 3: Performance measurement
Two measurements were taken at steady state to evaluate performance:
- Simulation Pace (speed up), which is the amount of hardware processing time (duration) required to advance the simulation 0.2 seconds. In general, a lower simulation pace indicates faster processing. The simulation speed up metric is used considering the CPU pace as reference.
- GPU Memory Usage, which is the amount of memory being used on the GPU while processing the simulation. In general, a lower memory usage allows for more particles to be processed, and/or more calculations to be performed.
Benchmark results for Ansys Rocky 2026 R1 – CFD-DEM Case
Relevant conclusions on simulation performance
Figure 16 shows the speed-up for the cyclone separator simulation using different combinations of GPU models and numbers.
- The results show a performance gain very interesting GPU performance. In a single GPU run it is possible to gain a speed-up about 18 times against a CPU run with 48 cores.
- For multi-GPU the same result can be achieved 31 times faster than using 48 CPU cores.
- The results show a great speed-up and good scalability and efficiency for a CFD-DEM simulation. Note: consider that this CFD-DEM simulation is processed with information from an external solver of Rocky (Ansys Fluent). Therefore, in this case data from Fluent needs to be passed to Rocky, which diminish the scalability and speed-up of Rocky.
Figure 16 – GPU speed-up based upon Simulation Pace (compared with CPU 48x cores) for CFD-DEM simulation.
Relevant conclusions on GPU memory consumption
In the cyclone separator analysis there is 185 million of sphere particles. Here, the sphere particles follows a PSD, as explained before. Figure 17 shows the GPU memory usage for the present case.
- The case use data from Fluent to coup with Rocky. However, the memory usage shown here concerns mostly to Rocky.
- As you can see the memory usage for multi-GPU (around 92 GB) is 17% higher than single GPU (around 77GB).
Figure 17 – Total GPU memory consumption for the CFD-DEM case.
Rocky GPU Performance Benchmark – SPH case
Smoothed Particle Hydrodynamics (SPH) is a meshless, Lagrangian computational method used to simulate the dynamics of continuum media, such as liquids and gases. Unlike traditional Grid-Based (Eulerian) methods that look at fluid passing through a fixed point, SPH follows the individual “elements” of the fluid as they move through space.
It is well-suited to evaluate free surface flows, such as fluid sloshing, dam breaks, tire aquaplaning and other similar phenomena. Its Lagrangian nature allows tracking fluid interfaces without complex pre-processing tasks or other techniques, for example, mesh-deformation algorithms.
The benefits of GPU
In any SPH simulation the fluid is discretized into millions of elements. On CPU hardware, the computations are processed via a limited number of high-performance concurrent cores compared to GPUs partition. In other words, one GPU computes thousands of mathematical operations when a CPU handles a few hundreds. Consequently, the computation time tends to be significantly reduced, allowing the SPH solver to scale more efficiently on GPU hardware due to the SPH algorithm’s inherently parallel nature.
Memory bandwidth plays an important role on SPH simulations. The SPH elements move and gather information of their neighbors at every time step. This leads to frequent, irregular memory access patterns. CPU can avoid waiting for memory using caches (L1, L2 or L3), but they lack memory bandwidth to handle millions of SPH elements efficiently. On the other hand, GPUs are designed for high workloads with a massive memory bandwidth. For example, comparing Intel Xeon Gold 6542Y and Nvidia H100 the ratio of memory between GPU/CPU is about 9 times for GPU, but this ratio can be even higher. Therefore, this superior data-transfer capability makes GPU the natural choice for large-scale SPH simulations.
Performance Benchmark
Criteria 1: SPH elements
To assess the performance of a Rocky SPH simulation we use a vehicle driving through a water puddle (car wading). The fluid is model using 16 millions of SPH elements and all geometries have about a total of 32 million triangles.

Figure 18 – SPH car wading simulation.
Criteria 2: Processing type
Four different processing combinations were evaluated:
- CPU: Intel(R) Xeon(R) Gold 6542Y CPU @ 2.90 GHz on 48 cores
- 1 GPU: NVIDIA H100, NVIDIA A100, NVIDIA L40
- 2 GPUs: NVIDIA H100, NVIDIA A100, NVIDIA L40
Criteria 3: Performance measurement
Two measurements were taken at steady state to evaluate performance:
- Simulation Pace (speed up), which is the amount of hardware processing time (duration) required to advance the simulation two seconds. In general, a lower simulation pace indicates faster processing. The simulation speed up metric is used considering the CPU pace as reference.
- GPU Memory Usage, which is the amount of memory being used on the GPU while processing the simulation. In general, a lower memory usage allows for more particles to be processed, and/or more calculations to be performed.
Benchmark results for Ansys Rocky 2026 R1 – SPH Case
Relevant conclusions on simulation performance
Figure 19 shows the performance speed-up for the IISPH solver in Ansys Rocky.
- The results show a huge performance gain of running a SPH simulation in a GPU. In the worst-case scenario, compared to a run in 48 CPU cores, you can reduce your simulation pace with one GPU in 23 times, approximately.
- The multi-GPU results also highlight the benefits of running SPH in a GPU, with two GPUs you can achieve a time reduction about 65 times compared with a 48 CPU cores.
Figure 19 – GPU speed-up based upon Simulation Pace (compared with CPU 48x cores) achieved for the SPH simulation.
Relevant conclusions on GPU memory consumption
Figure 20 shows the GPU memory usage for the SPH simulation within Ansys Rocky.
- A SPH simulation with 16 million SPH elements can be performed in just one GPU. Theoretically, it will be possible to run a case around 35 million SPH elements in 80 GB card, such as NVIDIA H100 NVL and NVIDIA A100 80GB PCIe.
- The maximum GPU memory consumption is about 27 GB in two GPUs. This result indicates that the SPH solver inside Rocky can be employed to analyze many complex problems.
Figure 20 – Total GPU memory consumption for the SPH simulation.
Ansys Rocky™ particle dynamics simulation software
Learn more about Rocky software in the Ansys Rocky Innovation Space.
-
















Introducing Ansys Electronics Desktop on Ansys Cloud
The Watch & Learn video article provides an overview of cloud computing from Electronics Desktop and details the product licenses and subscriptions to ANSYS Cloud Service that are...

How to Create a Reflector for a Center High-Mounted Stop Lamp (CHMSL)
This video article demonstrates how to create a reflector for a center high-mounted stop lamp. Optical Part design in Ansys SPEOS enables the design and validation of multiple...
Introducing the GEKO Turbulence Model in Ansys Fluent
The GEKO (GEneralized K-Omega) turbulence model offers a flexible, robust, general-purpose approach to RANS turbulence modeling. Introducing 2 videos: Part 1 provides background information on the model and a...

Postprocessing on Ansys EnSight
This video demonstrates exporting data from Fluent in EnSight Case Gold format, and it reviews the basic postprocessing capabilities of EnSight.

- Rocky GPU Buying Guide
- Enhance your simulations with Rocky Ready-to-use Modules
- Ansys Rocky 2024 R2 Release Highlights
- Ansys Rocky 2025 R1 Release Highlights
- Automate with Rocky Ready-to-use Scripts
- Ansys Rocky 2025 R2 Release Highlights
- Ansys Rocky 2024 R1 Release Highlights
- 5 great Rocky Modules to improve your simulations
- Customize with Ansys Rocky Solver SDK Package
- Ansys Rocky 2026 R1 Release Highlights

© 2026 Copyright ANSYS, Inc. All rights reserved.
