

Tagged: Code Generation, Integration, SCADE
-
-
January 31, 2024 at 10:54 am
 SolutionParticipant
SolutionParticipantIntroduction
When working on complex embedded systems with SCADE, a frequent strategy is to “divide and conquer” by breaking the system down into several models. Each model can be developed and validated on its own, ensuring that complexity and workloads remain manageable.
Once the models are correct, the whole system needs to be integrated. This involves generating C code, then integrating it with a small amount of manual code.
In this article, we will look at some strategies to achieve this.
Context
The SCADE language is modular; it maintains a strict separation between each operator’s interface and body. This is reflected by the possibility of generating one C function per selected (non-expanded) SCADE operator.
SCADE Suite KCG is the qualified code generator that comes with SCADE. It generates safe and efficient C code from a SCADE Suite model. Specifically, KCG outputs three kinds of files:
- Information files: logs, mappings, metrics…
- Fixed-name files:
kcg_sensors.h,kcg_types.h,kcg_consts.h,kcg_consts.c… - Application files: all other files containing C functions and types matching the model’s operators.
In this article, we will focus on building a single-process application with code generated from multiple SCADE models that communicate. For simplicity’s sake, we will leave scheduling out of the picture in this article (we could imagine there is a hand-coded scheduler on top of our application).
Integration strategies
In the following sections, we will review three integration strategies, building up to the most complex one.
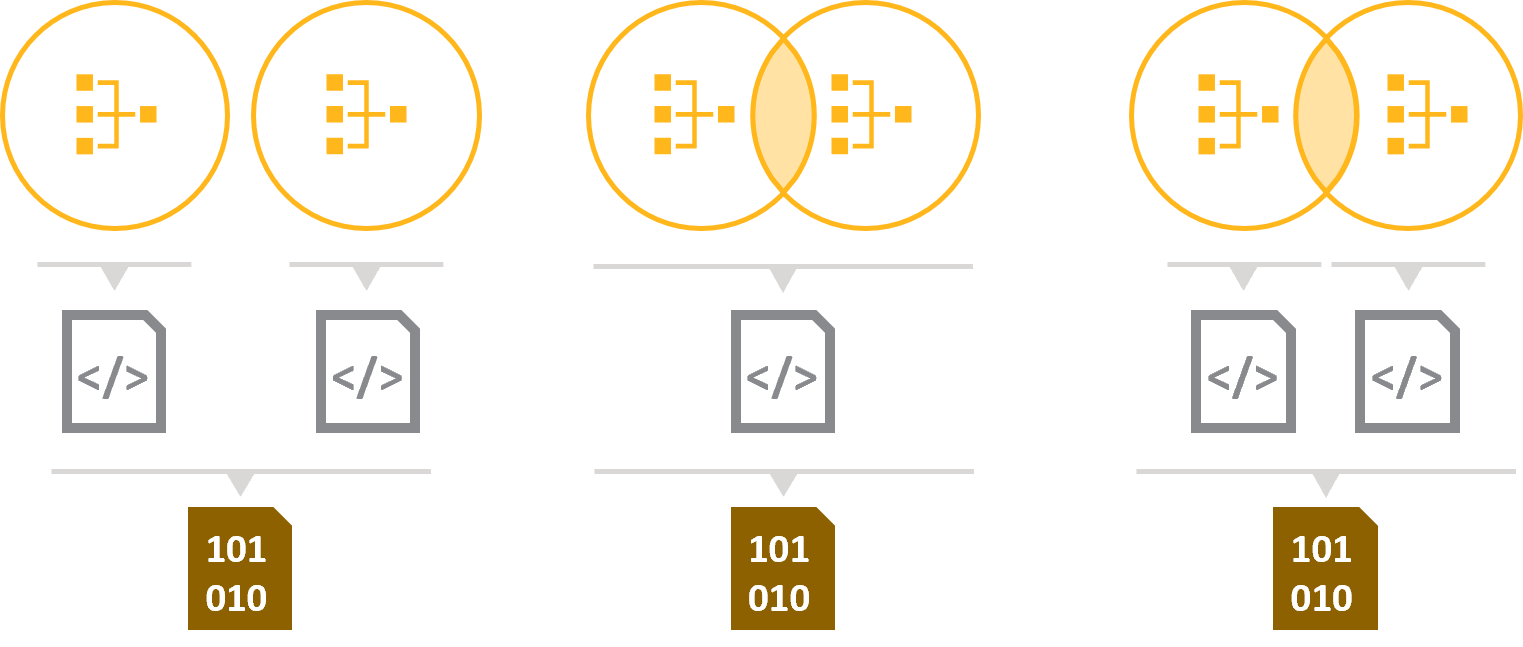
Three integration strategies to turn two SCADE models into one executableFrom left to right:
- Integrating independent models
- (Recommended) Integrating models that communicate with a single pass of code generation
- Integrating models that communicate with multiple passes of code generation
Strategy 1 – Independent models
In this case, the models perform functionally separate tasks.
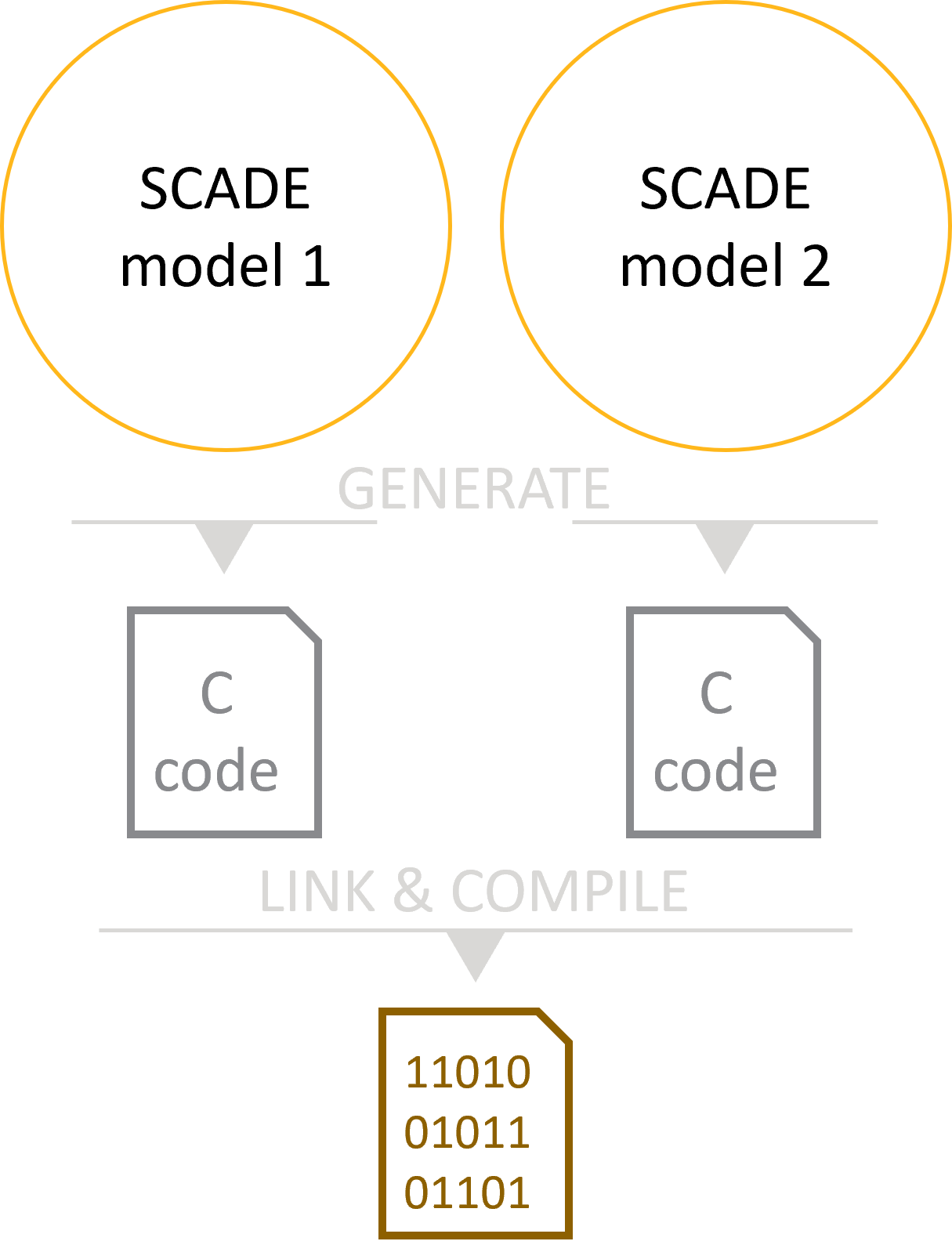
Strategy 1 at a glanceIf the models share absolutely nothing, you may generate and compile them separately, into separate target directories. Object code modules can then be linked.
Code generation settings for one of two independent modelsIf the models share some definitions, you may face naming conflicts at link time. Any item that is translated into a global C symbol may be in this case:
- (non-expanded) operators, generated as C functions (including common library operators and excluding imported operators)
- Constants, generated as C global variables/constants
- Sensors, accessed through C global variables
- Inputs/outputs, generated as C global variables/constants (with option
global_root_context)
Option
global_prefix(with a different value for each model) ensures that no name clashes happen at link time. Entities in the above list will be generated for each model, but under different names.Strategy 2 (Recommended) – Communicating models, single code generation pass
SCADE Suite KCG code generator is designed for verifying a complete application and generating the corresponding complete set of C files in one global run, ensuring maximum consistency of the generated code.
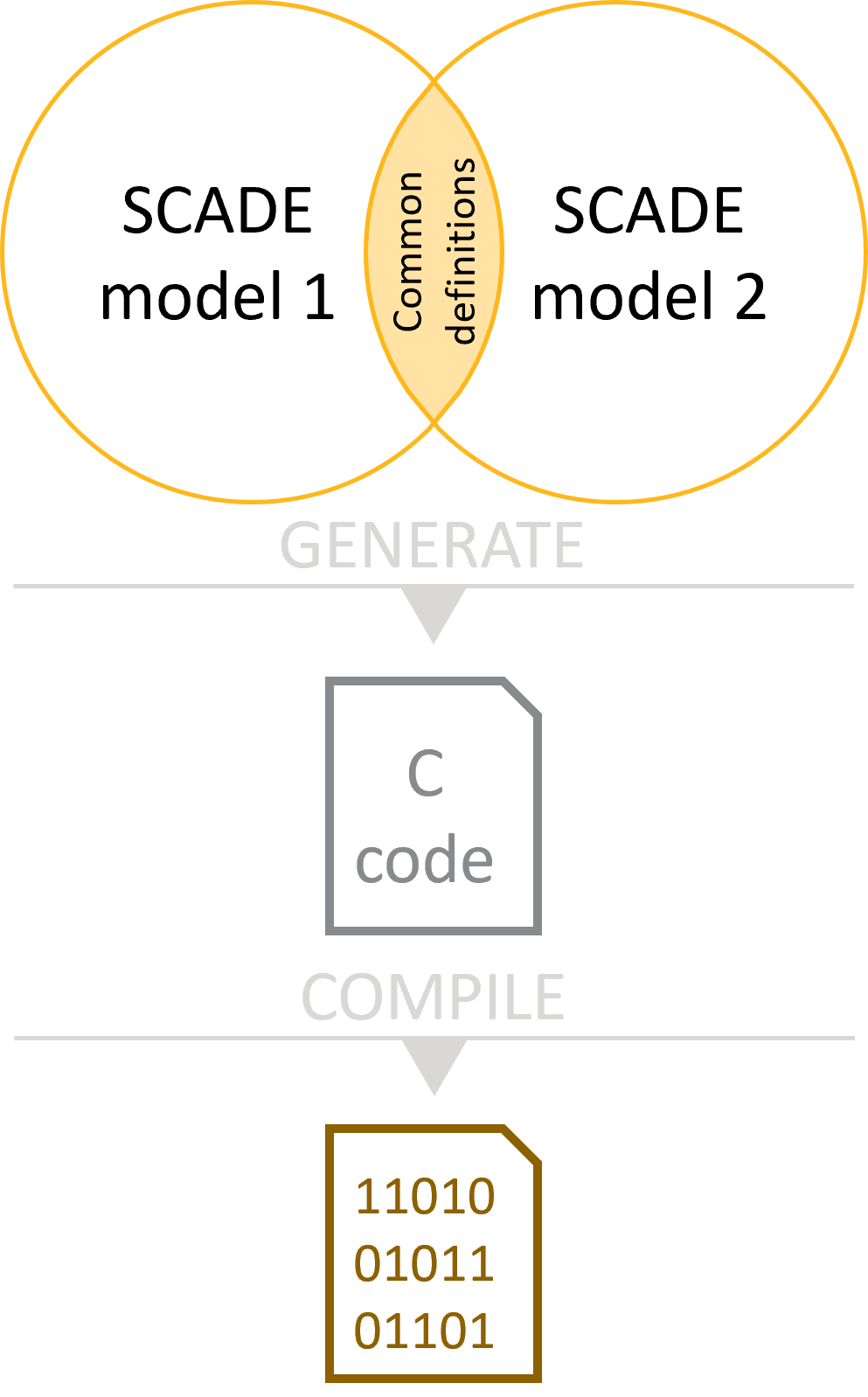
Strategy 2 at a glanceThis strategy is highly recommended unless there is a major reason for not using it. It is the safest and cleanest way to integrate multiple root operators. It is also highly recommended as a means of performing V&V of the overall behavior.
2.1 Preparation
Create a new empty model and add both models as libraries:
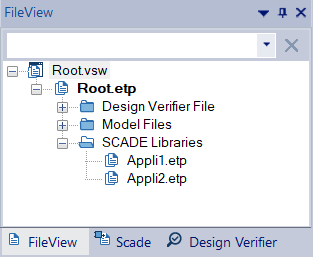
Two models to integrate, under the same SCADE root projectIdentify declarations used in both models and refactor them into a common library:
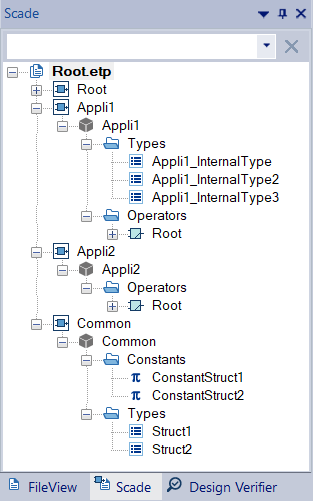
Common declarations in their own library2.2 Code generation
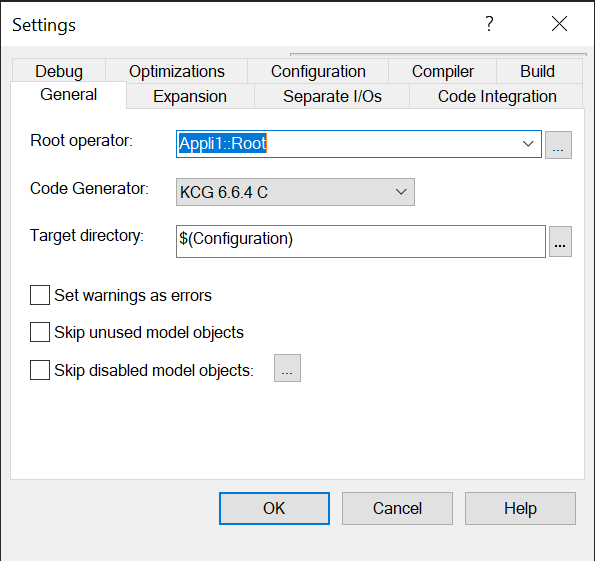
Select the root operators in the Code Generator Settings dialog:
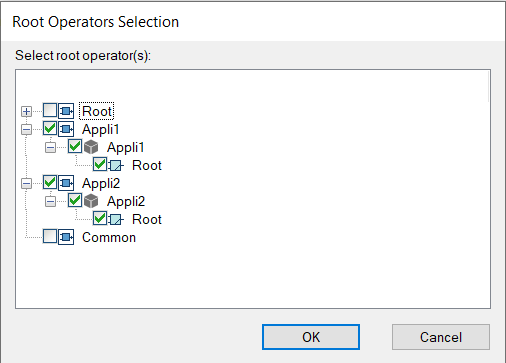
Code generator settings with both root operators selectedThe whole code is generated into a single target directory. Unique instances of fixed-name KCG files are (
kcg_types.h,kcg_consts.h, etc) are produced.Finish by writing manual integration code to call the functions of each root operator, cyclic, reset and initialization when available.
Strategy 3 – Communicating models, multiple code generation passes
This is the most complex approach: it uses separate code generation tasks for each model, followed by manual integration of the generated outputs.
This strategy is relevant when Strategy 2 cannot be used, the complexity of data exchanged between the models is low, and the size of each component is large.
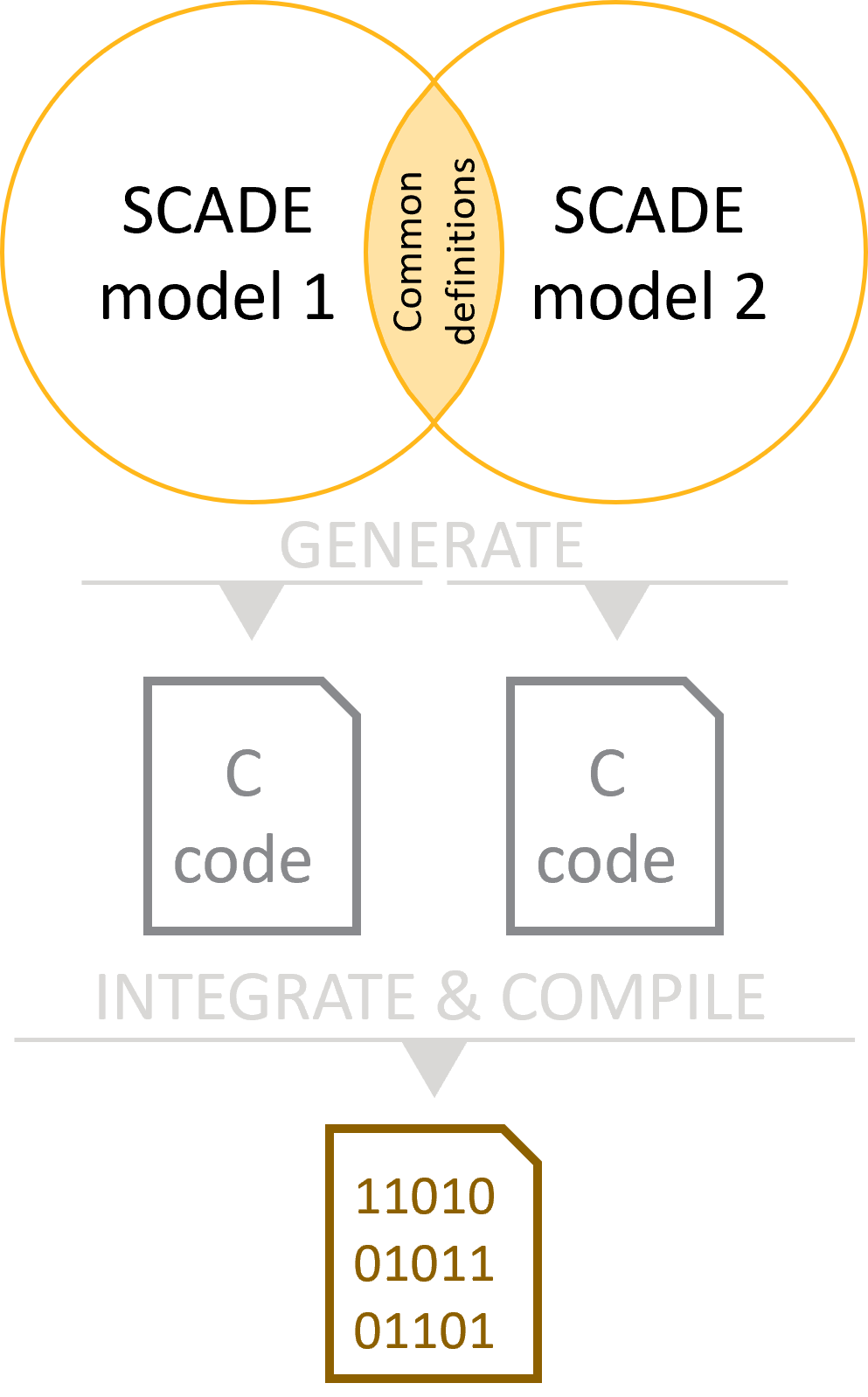
Strategy 3 at a glancePursuing this integration strategy requires solving several issues (we will refer to them as we tackle them):
- [IS1] Name conflicts on fixed-name KCG-generated files
- [IS2] Type definition conflicts during preprocessing
- [IS3] Conflicts during linking of parts common to both models (or linking of libraries)
- [IS4] Possibly different C names for common types in the generated code, preventing data integration between both parts
Some of these issues are pure compile/link time issues and can be easily fixed. The others are more complex. Although both sets of code are generated by KCG from consistent models, we must consider each generated codebase as manual code from the perspective of the other one. This means performing the same verifications that would be performed when integrating KCG generated code into an application, especially regarding I/O exchanges.
Let’s walk through this process step by step.
3.1 Model design
From the early design phase, you should define all shared entities, usually types and constants, in a dedicated SCADE project that is going to be used as a library by both SCADE models. This is not mandatory for later steps, but it’s a best-practice architecture decision.
In the example below, two SCADE models,
Appli1andAppli2, share some constants and type definitions. These shared objects should be declared in a dedicated SCADE project that is used as a library by both applications. This ensures the same type definition in each application. The C code that deals with these definitions, for communication purposes for instance, may include the definitions from either application.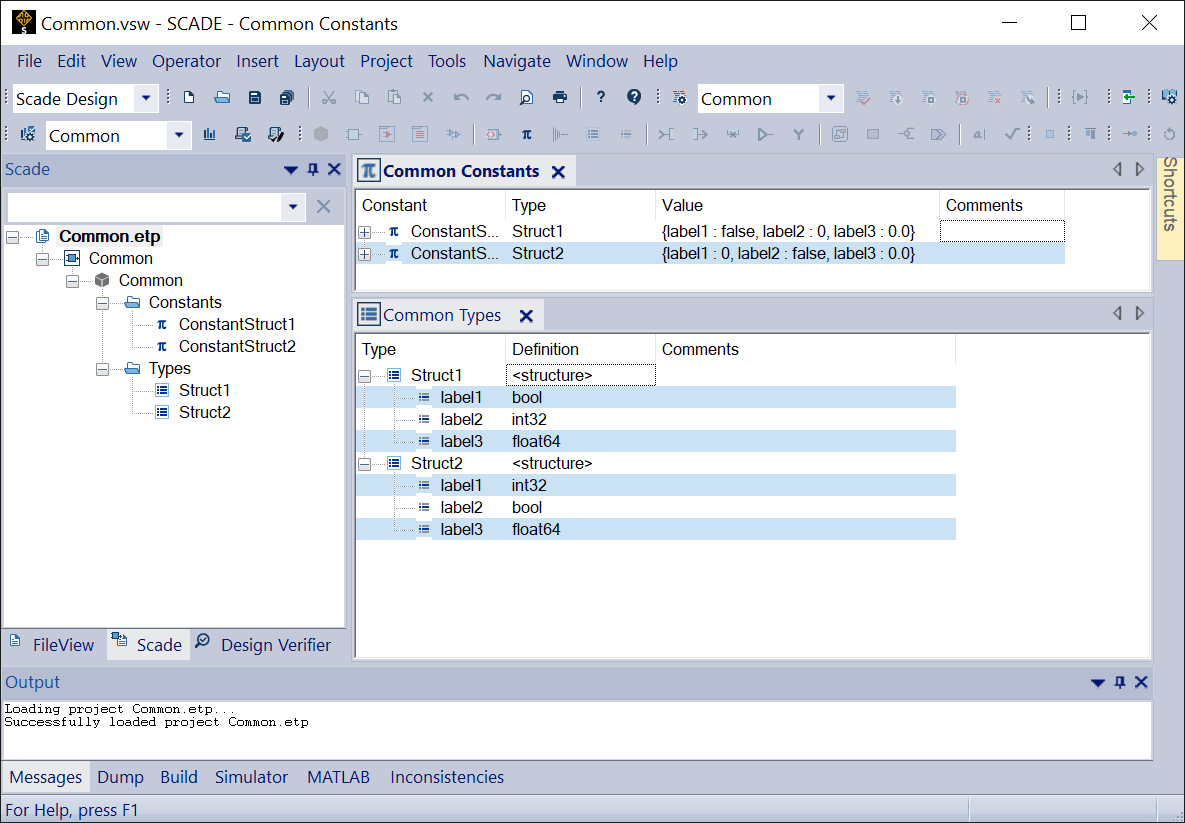
Common project with types and constantsBoth projects,
Appli1andAppli2, use theCommonproject as a library.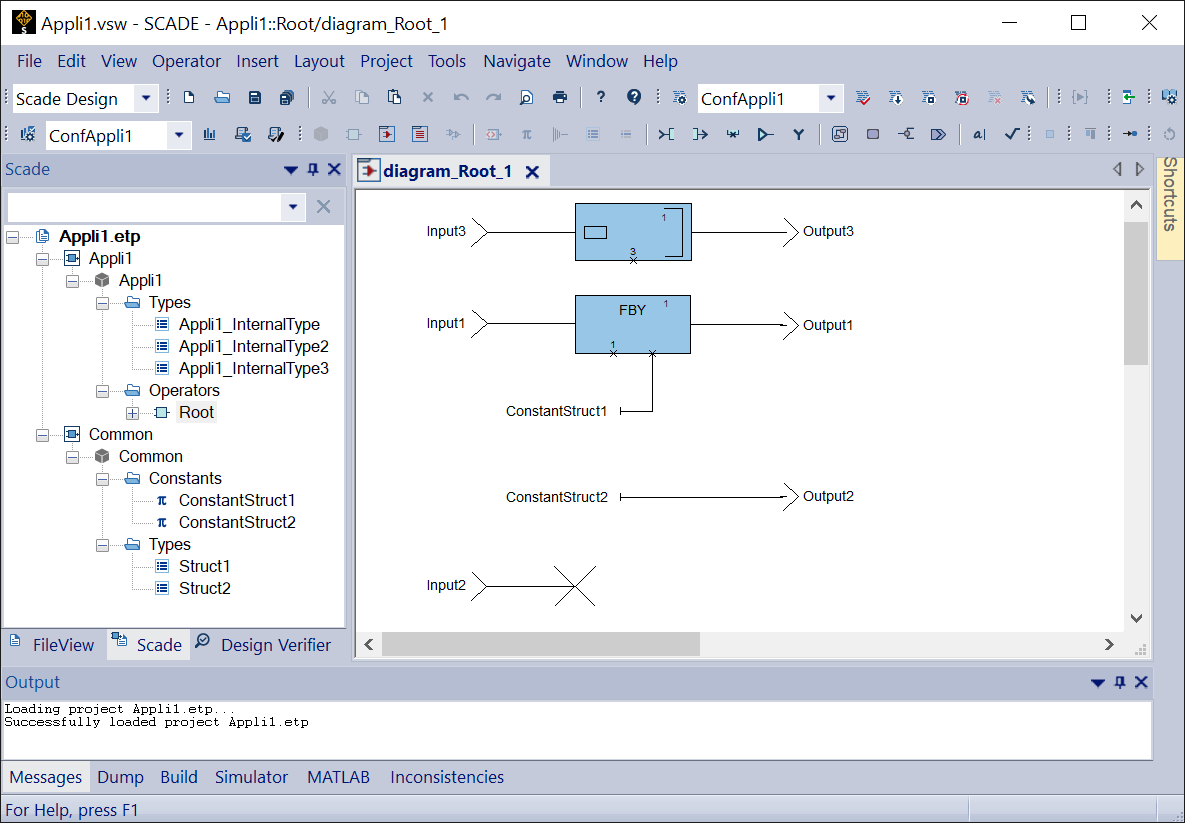
Appli1 project using Common as a libraryImportant note: never use KCG pragma
namefor objects that are accessible from both root operators. This will produce conflicts during later code integration.3.2 Code generation
Make sure code generation target directories are different for both projects. This is true by default when generating code from two different models. If both root operators belong to the same model, you should create two configurations, one per root operator, to store the code generation options.
You must use option
global_prefixto ensure different C names for data common to both SCADE models [IS2]: declarations (e.g. type names) and definitions (e.g. C library functions). You must also avoid double definitions in the link edition [IS3]. In the example, we use prefixesAp1/Ap2and target directoriesApp1/App2.With this in place, definitions from the
Commonproject appear both in filekcg_types.hand in the definitions ofAppli1. Here is an extract ofkcg_types.hgenerated in the context ofAppli1, usingAp1as global prefix:
#ifndef _Ap1_KCG_TYPES_H_
#define _Ap1_KCG_TYPES_H_
...
/* Appli1::Appli1_InternalType */
typedef struct Ap1_kcg_tag__2_Appli1_InternalType_Appli1 {
kcg_bool label1;
kcg_real label2;
} Ap1__2_Appli1_InternalType_Appli1;
...
/* Common::Struct2 */
typedef struct Ap1_kcg_tag_Struct2_Common {
kcg_int label1;
kcg_bool label2;
kcg_real label3;
} Ap1_Struct2_Common;
...
Using packages in the SCADE models helps distinguish the different declarations. In the example above, type
Common::Struct2is generated in the context of Appli2 asAp2_Struct2_Common. C names for these types,Common::Struct2in the example, differ in bothkcg_types.hfiles.Important note: C type names don’t need to be identical. The types are defined in different files and will therefore not be considered identical just because they have the same name. The only required similarity is for both declarations of the same type to be structurally equivalent.
3.3 Accessing multiple KCG-generated declarations
Let’s work on fixed-name file conflicts for generated files [IS1].
Conflicts usually happen when defining preprocessor
includedirectives:
-I <GENERATED_CODE_DIR>/App1/KCG60 -I <GENERATED_CODE_DIR>/App2/KCG60
In that case, integration source code cannot reliably access
kcg_types.hfiles:
#include "kcg_types.h"
/* Is this App1/KCG60/kcg_types.h? App2/KCG60/kcg_types.h? */
#include "kcg_types.h"
/* Is this App1/KCG60/kcg_types.h? App2/KCG60/kcg_types.h? */
The solution is to have the
includereference the common parent directory only:
-I <GENERATED_CODE_DIR>
Then, include the files as follows:
#include "App1/KCG60/kcg_types.h"
#include "App2/KCG60/kcg_types.h"
Note: you don’t need to add the path of the generated files to the list of directories to be searched when compiling the code generated by KCG. Compilation is fine: header and source files are generated in the same directory, and the generated C inclusion of header file uses quotes instead of brackets.
Note: one could argue that fixed-name files could simply receive a model-specific prefix to avoid conflicts. However, this would have undesirable technical implications: for instance, it wouldn’t be possible to write imported operators inside of libraries as their source code must include the KCG-generated type definition file. Therefore, fixed-name file names must be independent of code generator options.
3.4 Data integration
This is the trickiest part of the process. Not only do C types have different names in both sets of generated code [IS4], but the types are also different from the C compiler’s perspective. After all, they are defined in two distinct files, even if they are functionally equivalent.
There are two approaches to solving this. You may introduce a cast in the integration code, or stick to only exchanging scalar data. Selecting the best approach depends on your model: either one may pose performance or code size challenges. No matter your choice, you will need to perform additional verifications, either to ensure that the cast is correct (exact structural equivalence of the types) or that individual scalar assignments are complete and correct.
The next sections showcase an example of both possibilities: scalar copy and cast. The integration code needs to call
Appli1‘s root operator and copy its outputs into the inputs ofAppli2‘s root operator. Both are typed by the same typeCommon::Struct1in the SCADE model.Note: the example preserves the order of outputs and inputs.
Let’s start by pinpointing the type mismatch issue:
/* Sched.c - erroneous code */
#include "App1/KCG60/kcg_types.h"
#include "App2/KCG60/kcg_types.h"
void foo(...)
{
Ap1_inC_Root_Appli1 inCtx1;
Ap1_outC_Root_Appli1 outCtx1;
Ap2_outC_Root_Appli2 inCtx2;
Ap2_outC_Root_Appli2 outCtx2;
/* call to Appli1 */
Ap1_Root_Appli1(&inCtx1, &outCtx1);
/* data transfer from Appli1 to Appli2
* Type mismatch error */
inCtx2.Input2 = outCtx1.Output1;
/* call to Appli2 */
Ap1_Root_Appli2(&inCtx2, &outCtx2);
}
3.4.1 Scalar copy
This design simply copies each scalar value of the flattened structure.
/* Sched.c - individual assignments */
#include "App1/KCG60/kcg_types.h"
#include "App2/KCG60/kcg_types.h"
void foo(...)
{
/* contexts */
Ap1_inC_Root_Appli1 inCtx1;
Ap1_outC_Root_Appli1 outCtx1;
Ap2_outC_Root_Appli2 inCtx2;
Ap2_outC_Root_Appli2 outCtx2;
/* call to Appli1 */
Ap1_Root_Appli1(&inCtx1, &outCtx1);
/* data transfer from Appli1 to Appli2
* Individual assignments */
inCtx2.Input2.label1 = outCtx1.Output1.label1;
inCtx2.Input2.label2 = outCtx1.Output1.label2;
inCtx2.Input2.label3 = outCtx1.Output1.label3;
/* call to Appli2 */
Ap1_Root_Appli2(&inCtx2, &outCtx2);
}
Depending on the number of scalars in the structure, this method can quickly go out of hand. Code can become tedious to write (although it could be generated from the KCG trace file) and heavy to verify. Moreover, this larger code quantity could degrade runtime efficiency.
3.4.2 Cast
This design is the simplest and most efficient. Configuration management and project plans guarantee that type declarations are consistent on both sides. They have been obtained from the same SCADE model, generated with the same options.
Note: if desired, it is possible to generate verifications checked at compile time, based on size and offsets, to make sure the cast is legal. However, such a verification tool cannot be used to verify the overall process.
/* Sched.c - CAST */
#include "App1/KCG60/kcg_types.h"
#include "App2/KCG60/kcg_types.h"
void foo(...)
{
/* contexts */
Ap1_inC_Root_Appli1 inCtx1;
Ap1_outC_Root_Appli1 outCtx1;
Ap2_outC_Root_Appli2 inCtx2;
Ap2_outC_Root_Appli2 outCtx2;
/* call to Appli1 */
Ap1_Root_Appli1(&inCtx1, &outCtx1);
/* data transfer from Appli1 to Appli2
* Cast */
inCtx2.Input2 = (Ap2_Struct1_Common *) outCtx1.Output1;
/* call to Appli2 */
Ap1_Root_Appli2(&inCtx2, &outCtx2);
}
3.4.3 Variants
There are many other solution variants, such as introducing wrappers to reduce dependencies between the C code pieces, or writing generators to generate types from the Common project. Ultimately, all these variants rely on the above two proposals.
3.5 Importing code
One final challenge remains: if either model uses imported code, it needs to be properly integrated into our multiple code generation flow:
- Resolve possible conflicts around the name of the imported operator. It is usually required to set a KCG pragma name to make sure the C name of the imported operator, written once, is not impacted by the KCG options.
- Resolve possible conflicts on the type names of imported operator inputs/outputs, using techniques discussed in the previous sections.
3.5.1 Predefined Type Parameters
Imported operators having only parameters with predefined types are not an issue. As explained above, the name does not depend on the code generation options, thanks to KCG pragma
name: ExternalScalar_Common.The declaration is then protected against multiple definitions.
#ifndef ExternalScalar_Common
/* Common::ExternalScalar */
extern kcg_real ExternalScalar_Common(kcg_real Input);
#endif /* ExternalScalar_Common */
The C file containing the implementation must be added only once to the link edition process.
3.5.2 Model Type Parameters
Some imported operators may have some parameters with a user-defined type. Should the type or operator be used by both models, action is required to avoid conflict. As seen in data integration above, ground rules are:
- The type and operator must be defined in the common library.
- Option
global_prefixmust be used. - Pragma
namecannot be used.
The declaration of the imported operator is different in the context of both code generations.
Here it is for
Appli1:
#ifndef Ap1_Operator1_Common
/* Common::Operator1 */
extern void Ap1_Operator1_Common(
Ap1_Struct1_Common *Input,
/* Common::Operator1::Output */ Ap1_Struct1_Common *Output);
#endif /* Ap1_Operator1_Common */
And for
Appli2:
#ifndef Ap2_Operator1_Common
/* Common::Operator1 */
extern void Ap2_Operator1_Common(
Ap2_Struct1_Common *Input,
/* Common::Operator1::Output */ Ap2_Struct1_Common *Output);
#endif /* Ap2_Operator1_Common */
To complete compilation and link edition, the imported operator must be declared in a C file with a generic name:
/* generic_operator1_common.c */
#include "kcg_types.h"
void Generic_Operator1_Common(Generic_Struct1_Common *Input, Generic_Struct1_Common
*Output);
{
...
}
This C file must then be compiled twice by defining the appropriate include directives:
cc -c -I "App1/KCG60" \
-DGeneric_Operator1_Common Ap1_Operator1_Common \
-DGeneric_Struct1_Common Ap1_Struct1_Common \
-o ap1_operator1_common.o generic_operator1_common.c
cc -c -I "App2/KCG60" \
-DGeneric_Operator1_Common Ap2_Operator1_Common \
-DGeneric_Struct1_Common Ap2_Struct1_Common \
-o ap2_operator1_common.o generic_operator1_common.c
3.5.2 Library Type Parameters
If the imported operator and type are both defined in a library and declared with KCG pragma
name, the solution consists of considering the name of the operator and the type as generic, like in the previous sections, and reusing the same mechanism for the whole files: re-introduce a prefix.The source of the imported operator must be compiled with the same options as defined in the previous section.
The generated code for
Appli1andAppli2must be compiled with similar options:
-DOperator1_Common Ap1_Operator1_Common -DStruct1_Common Ap1_Struct1_Common
And
-DOperator1_Common Ap2_Operator1_Common -DStruct1_Common Ap2_Struct1_Common
The integration file requires incorporating these macro definitions since it refers to both
kcg_types.hfiles.
/* Sched.c - Imported operators */
#define Operator1_Common Ap1_Operator1_Common
#define Struct1_Common Ap1_Struct1_Common
#include "App1/KCG60/kcg_types.h"
#undef Operator1_Common Ap2_Operator1_Common
#undef Struct1_Common Ap2_Struct1_Common
#define Operator1_Common Ap2_Operator1_Common
#define Struct1_Common Ap2_Struct1_Common
#include "App2/KCG60/kcg_types.h"
void foo(...)
{
/* contexts */
Ap1_inC_Root_Appli1 inCtx1;
Ap1_outC_Root_Appli1 outCtx1;
Ap2_outC_Root_Appli2 inCtx2;
Ap2_outC_Root_Appli2 outCtx2;
/* call to Appli1 */
Ap1_Root_Appli1(&inCtx1, &outCtx1);
/* data transfer from Appli1 to Appli2
* Cast */
inCtx2.Input2 = (Ap2_Struct1_Common *) outCtx1.Output1;
/* call to Appli2 */
Ap1_Root_Appli2(&inCtx2, &outCtx2);
}
In summary
Here’s a pros / cons summary for each strategy we reviewed:
Strategy Pros Cons 1. Independent models + Extremely simple – Situational: only applies to applications built from independent models 2. Communicating models, single code generation pass (Recommended)
+ Code describing shared types is guaranteed to be completely consistent (no code duplication) + Single target directory for generation, leading to a simpler integration makefile
+ Types are uniquely defined
+ No conflicts, either for the C compiler or for the linker
– Updating one SCADE model requires regenerating the complete application code 3. Communicating models, multiple code generation passes + No need to introduce a dummy wrapper operator + Updating one model does not imply recompiling the complete application code
– Requires strict interface consistency verification and integration testing – C names include an additional prefix, making interfaces more verbose
– Common operator code is generated/compiled/linked twice, leading to a larger generated codebase
– May require additional manual integration code that is costly to write and verify
– Often incompatible with models using KCG pragma
name, e.g. in libraries defining imported operatorsReady to dive in?
We hope this article helps guide you in integrating SCADE models together. If you have questions or feedback, don’t hesitate to ask our Ansys expert community.
About the author

Jean Henry (LinkedIn) is a Senior Principal Product Specialist at Ansys. He has been working on the SCADE product since its inception, more than 30 years ago. He has expertise in software development, testing and integration.
-


Introducing Ansys Electronics Desktop on Ansys Cloud
The Watch & Learn video article provides an overview of cloud computing from Electronics Desktop and details the product licenses and subscriptions to ANSYS Cloud Service that are...

How to Create a Reflector for a Center High-Mounted Stop Lamp (CHMSL)
This video article demonstrates how to create a reflector for a center high-mounted stop lamp. Optical Part design in Ansys SPEOS enables the design and validation of multiple...
Introducing the GEKO Turbulence Model in Ansys Fluent
The GEKO (GEneralized K-Omega) turbulence model offers a flexible, robust, general-purpose approach to RANS turbulence modeling. Introducing 2 videos: Part 1 provides background information on the model and a...

Postprocessing on Ansys EnSight
This video demonstrates exporting data from Fluent in EnSight Case Gold format, and it reviews the basic postprocessing capabilities of EnSight.

- An introduction to DO-178C
- ARINC 661: the standard behind modern cockpit display systems
- Scade One – Bridging the Gap between Model-Based Design and Traditional Programming
- Scade One – An Open Model-Based Ecosystem, Ready for MBSE
- Scade One – A Visual Coding Experience
- Using the SCADE Python APIs from your favorite IDE
- SCADE and STK – Satellite Attitude Control
- How to integrate multiple SCADE models into one executable
- Introduction to Formal Verification and SCADE Suite Design Verifier
- Scade One – Democratizing model-based development

© 2026 Copyright ANSYS, Inc. All rights reserved.

{kind=link}