Hi Peter, From Internet, I have found a formula,
x = 0.025 m
acceleration = 4*π^2*f^2*x = 0.2467 m/s^2
I am not sure, which method is correct
As you suggested,
f = 0.5 Hz
A = 0.025 m/s
w = 2*pi*f = 3.14159 rad/sec
velocity = A*sin(w*t)
t = 2 seconds
acceleration = A*w*sin(w*t) ---- As you said I have taken the derivative
= A*(2 * pi * f) * sin(w*t)
= 0.025*(2*3.1416*0.5)*sin(3.1416 * 2)
= 0.00859 m/s^2
Please give me a suggestion as to which value of acceleration I should take.
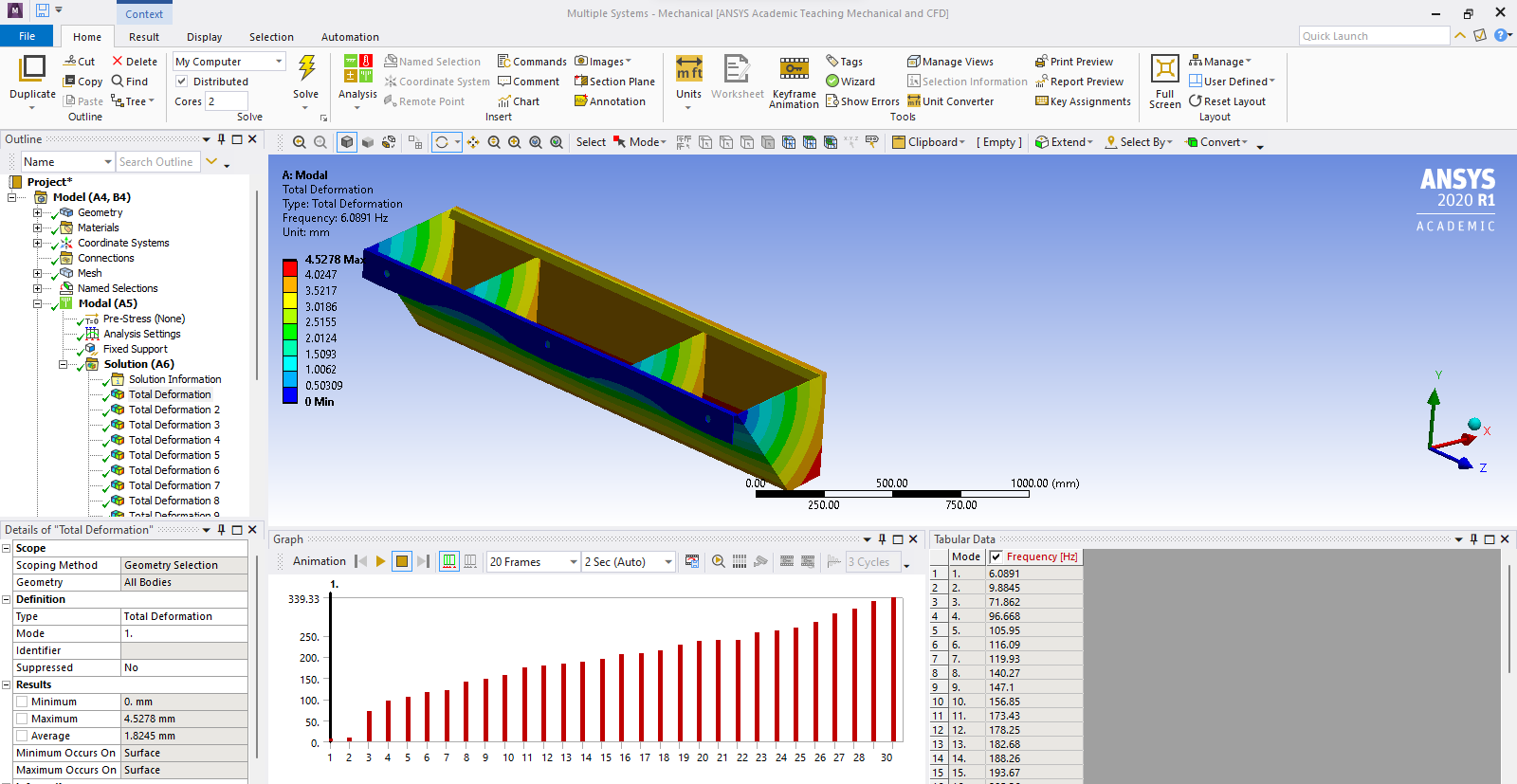
The tank is half filled with free surface with air at the top.