

-
-
March 16, 2022 at 10:50 am
amnonjw
SubscriberI defined a resource that uses the job scheduler to run Lumerical simulations on a remote cloud server. I replaced the sge.py file in the job_schedulers folder (see attached script in 7z file).
Our jobs manager doesn't create the .o files immediately so instead I created a code that can retrieve the log file from the server, opens it and find the lines with the progress % updates. I see that in the sge.py file you just print the lines of the updates. When I do this there's no update in the Lumerical window of the running jobs - the status remains "running".
Can you check to see what I'm doing wrong?
March 16, 2022 at 4:52 pmLito
Ansys EmployeeAre you running the simulation from your local Windows PC and submitting this to the cluster from the Lumerical CAD/GUI as shown in this article in the KB? Did you configure your PC as outlined in the article?
We cannot download files/attachments from the forum. If you want to share your code/script, kindly paste this on your post.
March 24, 2022 at 7:41 amSubscriberHi I followed the article you mentioned in KB, and did my own modification to work with our PBS queue manager - for that I had to overwrite the exiting file sge.py. It work correctly in communicating with the remote server. I now want to add status updates on the job progress.
In the original sge.py (line 196) there's a comment on how to update the job manager in the local Lumerical application:
# Update the simulation progress (%) in the Lumerical Job manager. SGE writes the stdout of the engine job to a .out file. We send this information back to the job manager and cache the result from previous updats so only new updates are sent.
In the method I use ("update_progress_from_log_file" instead "update_progress_from_stdout_file") I print the lines of the updates but there's no update in the Lumerical window of the running jobs.
# new methods #
def get_log_file(fsp_basename):
cmd = ['scp', SSH_LOGIN + ':' + CLUSTER_CWD + fsp_basename + '_p0.log', '.']
try:
call(cmd)
file_handle = io.open(fsp_basename + '_p0.log',"r")
lines = file_handle.readlines except Exception as ex:
log(f'Copying remote file to local host. Calling command {" ".join(cmd)}')
log(traceback.format_exc())
lines = []
return lines
status_line_marker = "complete. Max time remaining"
def update_progress_from_log_file(log_lines, last_line):
if (len(log_lines)-1 != last_line):# there was a change in the log content
for i_line in range(last_line, len(log_lines)):
if status_line_marker in log_lines[i_line]:
log(log_lines[i_line])
print(log_lines[i_line])
sys.stdout.flush last_line = i_line
return last_line
# modified methods #
def run_job(submission_script_lines, submission_command):
assert((len(submission_command) > 0))
submission_script_lines, local_path, filename, basename = parse_submission_script(submission_script_lines)
if USE_SSH and USE_SCP:
put(local_path)
job_id = submit_job(submission_script_lines, submission_command, basename)
sleep(0.5)
assert(job_in_queue(job_id))
print("QUEUED ")
sys.stdout.flush while job_status(job_id,basename) == 'Q':
sleep(1)
if job_status(job_id,basename) == 'R':
print("RUNNING ")
sleep(2) # wait before attempting to retrieve the log file
last_log_line = -1 # the last line read in previous reading of the log file
while job_status(job_id,basename) != 'C':
log_lines = get_log_file(basename)
last_log_line = update_progress_from_log_file(log_lines,last_log_line)
sleep(1)
if USE_SSH and USE_SCP:
remote_clean(basename)
get(basename)
def submit_job(submission_script, submission_command, job_name):
cmd = submission_command + ['-N', job_name]
if USE_SSH:
cmd = ssh_wrapper(cmd)
log('Submission Command: ' + ' '.join(cmd))
log('Submission Script:\n' + '\n'.join(submission_script))
p = subprocess.Popen(cmd, shell=True,stdin=subprocess.PIPE,stdout=subprocess.PIPE, encoding='utf8', universal_newlines=True)
p.stdin.buffer.write('\n'.join(submission_script).encode()) # ensure unix style line endings are used
p.stdin.close result = p.stdout.readlines log('Submission Response:\n' + '\n'.join(result))
result = result[0].split('.')
job_id = result[0]
assert(job_id.isdigit())
log(f'Submission successful, Job ID: {job_id}')
return job_id
def job_status(job_id,basename):
cmd = ['qstat', job_id]
if USE_SSH:
cmd = ssh_wrapper(cmd)
try:
job_status = check_output(cmd)
for line in job_status.splitlines():
possible_job_id = line.strip().split()[0]
possible_job_id = possible_job_id.split('.')[0]
if possible_job_id == str(job_id):
status = line.strip().split()[4]
sys.stdout.flush return status
except subprocess.CalledProcessError as e:
print("python subprocess error - possible job finished and popped out of queue table")
status= 'C'
print("")
print("")
return status
p.s.
Your forum accepts uploading files, so I don't understand why you have this feature if you're not allowed to download files on your side... How else are we going to help you reproduce the issues that we're having?
March 25, 2022 at 4:14 pmAnsys EmployeeSee the Ansys forum guidelines for details on posting. Let me check the scripts/modifications. In the meantime, are you trying to run optimizations from your local Windows PC remotely to your cluster? Or 1 simulation file or a parameter sweep on your cluster? Does your cluster allow GUI/graphical access?
March 27, 2022 at 10:49 amSubscriberThe server allows to open a GUI, but I don't think it can run for a long time due to server resource constraints.
Because of this - my aim is that a sweep or iterations of inverse design are managed in the local computer, such that the files are prepared locally and sent to run on the remote server (with the actual "horse-power") using the PBS queue.
March 30, 2022 at 7:33 amGreg Baethge
Ansys Employee
asked me to check this as I have some experience with our job scheduler integration (although mostly with Slurm and SGE). I'm not familiar with PBS, but Torque, that is a scheduler we support, is a fork of PBS. In torque.py, I noted a comment:
 To be honest, I don't know what is the limitation here or if it is possible to overcome it. That said, we can try and troubleshoot it. The easiest way would be to run the scheduler integration out of the GUI, so we can check the output of the methods such as update_progress_from_log_file. What you can do is write a Python script where you define a test submission script and submission command, import the modified sge.py and call its run_job function.
To be honest, I don't know what is the limitation here or if it is possible to overcome it. That said, we can try and troubleshoot it. The easiest way would be to run the scheduler integration out of the GUI, so we can check the output of the methods such as update_progress_from_log_file. What you can do is write a Python script where you define a test submission script and submission command, import the modified sge.py and call its run_job function.
March 31, 2022 at 10:03 amSubscriberHi Greg, thanks for the help.
I currently run my jobs from the GUI, and I check the output using the "view job details" option. I see that the print updates are done to the std-output and they appear in the details log. This is the best for now, My goal was to make this show in the Job Manger table, like it was a local job.

I too noticed the comment in the Torque.py file, but I noticed also that for sge.py this comment doesn't appear, and in that python code - you just print the progress lines from the output-file of the simulation. This is the code from sge.py
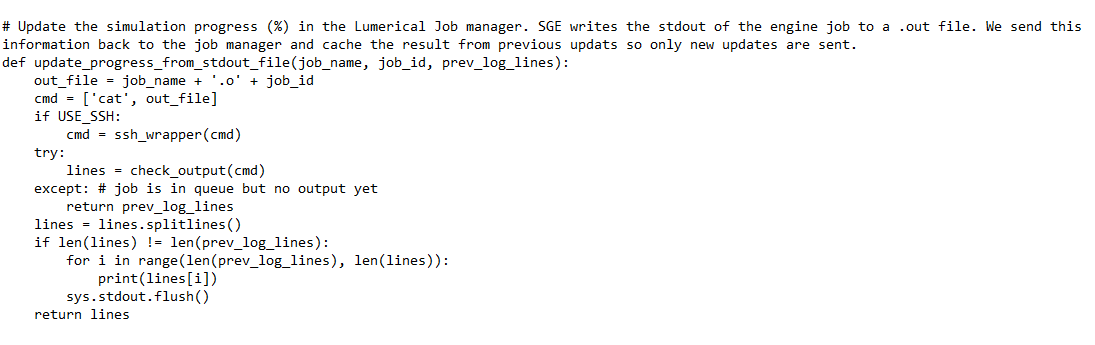 I (naively) thought that the GUI allows output updates from an sge implementation and blocks any updates from a torque implementation, so I overwritten the sge.py script with the script I use to communicate with the cluster job manager, and added my code for update_progress_from_log_file, in which I too "just print the lines". I thought that the GUI will accept it, parse the printed lines, and show the progress in the GUI's job manager, but it doens't.
I (naively) thought that the GUI allows output updates from an sge implementation and blocks any updates from a torque implementation, so I overwritten the sge.py script with the script I use to communicate with the cluster job manager, and added my code for update_progress_from_log_file, in which I too "just print the lines". I thought that the GUI will accept it, parse the printed lines, and show the progress in the GUI's job manager, but it doens't.
March 31, 2022 at 12:11 pmAnsys Employee
I had a closer look at this and I also ran some tests on our HPC. I realized the progress update doesn't work either. It seems related to changes we made in how we control the job manager window to accommodate our other solvers. As a result, it is much more flexible, but also more complex to manage.
Basically, the job manager window is expecting some xml tags. A first series will create additional column like the max time remaining, autoshutoff level and progress, for instance, then these fields will be updated. Note the engine, status and project file columns are there by default.
I managed to add the progress, so it should be possible to add the other ones as well, but it requires some work. You also need to parse the simulation log to separate the different values to update in the job manager window. If you're interested, the syntax I found is something like:
To add columns:
Meshing Status
text
meshstatus
Type can be text or progress. Other values might be possible. The tagname will be used to update the field. You can add several columns in the same block.
Building geometry
I got this by looking at the output of other solvers. I'll see if I can get our scripts updated for a future release. It will require some more work to make sure it will work for all our solvers.
March 31, 2022 at 1:54 pmAnsys Employee
Looks like I managed to accidentally delete my reply... I'll try again... I ran some tests on our own HPC, the progress update doesn't work either. I think we changed the way the job manager window works to accommodate the output of our different solvers. As a result, printing the output of FDTD is not enough to update the status and progress. The software is expecting some xml tags instead.
I played with it and I managed to at the progress to a simulation. It works in 2 phases: first, you need to define the fields that will be shown in addition to "Engine", "Status" and "Project file".
Meshing Status
text
meshstatus
You can add multiple columns. The title will be shown in the window, type can be text or progress and tagname is used to update the field.
Building geometry
To get the full update, you need to parse the output of FDTD to get the progress (just the number, no % sign), etc.
I'll see if our scripts can be updated in a next release. It will require some work to make sure it works with all our solvers. Alternatively, we could update FDTD so its output is the same as other solvers like HEAT (that I used to get the syntax above).
April 3, 2022 at 1:59 pmSubscriberHi Greg Your instructions were on point. Thanks for the help.
I can email you my code in case your team want to incorporate this in your next release.
April 4, 2022 at 9:17 amAnsys EmployeeYou're most welcome,,glad I could help. I'll check with the team. I think we either need to update the scripts or FDTD so its output is consistent with the other solvers. I will also investigate the behavior with other solvers. The easiest will be to update the python scripts, I just need to make sure the code will work with all solvers' output.
April 5, 2022 at 7:56 amAnsys Employee
I had a chance to check with my colleagues, this is not documented but to get the proper output from FDTD, you need to add the -remote flag to the command in your submission script. With this, the output will be the required xml data that will update the progress, etc. It would be something like, for example:
mpirun /opt/lumerical/v221/bin/fdtd-engine-impi-lcl -logall -remote {PROJECT_FILE_PATH}
Here we use Intel MPI, replace the engine with the version corresponding to the MPI implementation you are using.
With this flag, there is no need to adapt the Python script to generate the xml. Sorry I didn't figure this out earlier, it would have saved you some time!
Viewing 11 reply threads- The topic ‘Status updates when using remote job scheduler’ is closed to new replies.
Ansys Innovation Space Trending discussions
Trending discussions Top Contributors
Top Contributors
-
peteroznewman
 3467
3467 -
javat33489
 1057
1057 -
scabo
 1051
1051 -
Dennis Chen
 918
918 -
Shyam Prasad V Atri
896
Top Rated Tags
© 2025 Copyright ANSYS, Inc. All rights reserved.
Ansys does not support the usage of unauthorized Ansys software. Please visit www.ansys.com to obtain an official distribution.
-





The Ansys Learning Forum is a public forum. You are prohibited from providing (i) information that is confidential to You, your employer, or any third party, (ii) Personal Data or individually identifiable health information, (iii) any information that is U.S. Government Classified, Controlled Unclassified Information, International Traffic in Arms Regulators (ITAR) or Export Administration Regulators (EAR) controlled or otherwise have been determined by the United States Government or by a foreign government to require protection against unauthorized disclosure for reasons of national security, or (iv) topics or information restricted by the People's Republic of China data protection and privacy laws.



