Hello Santiago,
The file ending with .I2a is not the LS-DYNA solver. Please take the other file in the folder:
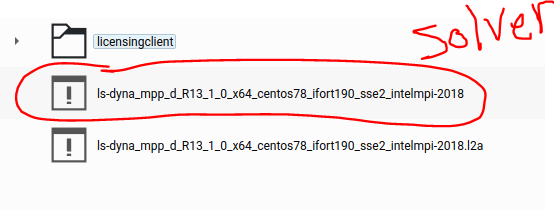
Here are the commands I use to run LS-DYNA on LInux:
SMP:
/data2/rgenest/lsdyna/ls-dyna_smp_d_R13_0_0_x64_centos610_ifort190/ls-dyna_smp_d_R13_0_0_x64_centos610_ifort190 i=/data2/rgenest/runs/Test/input.k ncpu=-4 memory=20m
Note that for SMP, we recommend setting ncpu=-4 (that is a negative number of cpus). The negative means that the solver will use consistency checking to get consistent results with different number of cores.
MPP:
To run MPP, we specify the location of the mpiexec or mpirun file first.
Intel MPI:
/data2/rgenest/intel/oneapi/mpi/2021.2.0/bin/mpiexec -np 4 /data2/rgenest/lsdyna/ls-dyna_mpp_d_R13_0_0_x64_centos610_ifort190_sse2_intelmpi-2018/ls-dyna_mpp_d_R13_0_0_x64_centos610_ifort190_sse2_intelmpi-2018 i=/data2/rgenest/runs/Test/input.k memory=20m
Platform MPI:
/data2/rgenest/bin/ibm/platform_mpi/bin/mpirun -np 4 /data2/rgenest/lsdyna/ls-dyna_mpp_d_R13_0_0_x64_centos610_ifort190_sse2_platformmpi/ls-dyna_mpp_d_R13_0_0_x64_centos610_ifort190_sse2_platformmpi i=/data2/rgenest/runs/Test/input.k memory=20m
Open MPI:
/opt/openmpi-4.0.0/bin/mpirun -np 4 /data2/rgenest/lsdyna/ls-dyna_mpp_d_R13_0_0_x64_centos610_ifort190_sse2_openmpi4/ls-dyna_mpp_d_R13_0_0_x64_centos610_ifort190_sse2_openmpi4.0.0 i=/data2/rgenest/runs/Test/input.k memory=20m
You will have to modify the above commands for your own path for the LS-DYNA solver, the MPI mpiexec file, and the input file.
Let me know how it goes.
Reno.

















