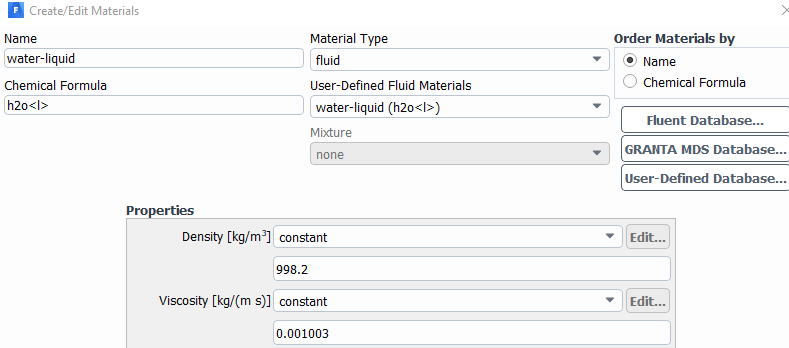
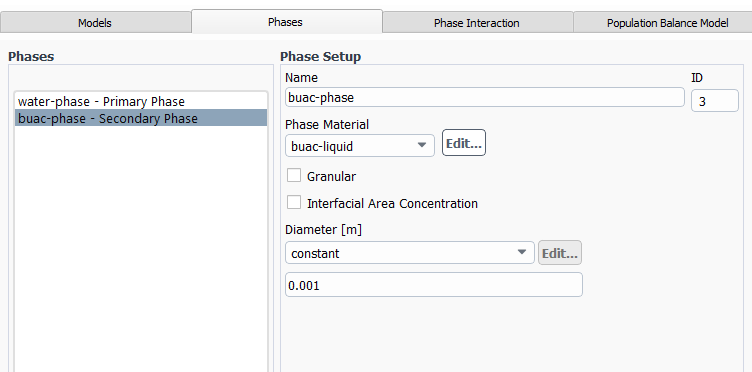
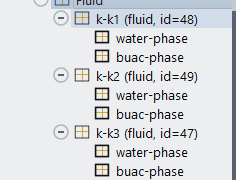
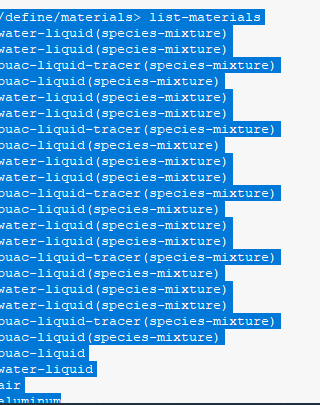
Thanks. There is also another problem that the if I simulate with 1 Node(20 tasks per node--> so 20 partitions) I get this error message:
==============================================================================
===================================================================================
=BAD TERMINATION OF ONE OF YOUR APPLICATION PROCESSES
=PID 4882 RUNNING AT cstd02-049
=EXIT CODE: 9
=CLEANING UP REMAINING PROCESSES
=YOU CAN IGNORE THE BELOW CLEANUP MESSAGES
===================================================================================
Intel(R) MPI Library troubleshooting guide:
https://software.intel.com/node/561764
=====
When simulating with one node it uses too much memory:
> timekbmemused
> 10:40:01 AM11605588
> 10:50:01 AM14114168
> 11:00:01 AM16619788
> 11:10:01 AM18385440
> 11:20:01 AM20677200
> 11:30:01 AM22551200
> 11:40:01 AM24563312
> 11:50:01 AM27044424
> 12:00:01 PM28601752
> 12:10:02 PM30850688
> 12:20:01 PM32915072
> 12:30:01 PM35065452
> 12:40:01 PM36657816
> 12:50:01 PM38874056
> 01:00:01 PM41414584
> 01:10:01 PM43445944
> 01:20:01 PM44990388
> 01:30:01 PM47385076
> 01:40:01 PM49660092
> 01:50:01 PM51335148
> 02:00:01 PM53959052
> 02:10:01 PM56032252
> 02:20:01 PM58121960
> 02:30:01 PM59675572
> 02:40:01 PM61839556
Then there is not ennough RAM availlable for that problem.
If i simulate with 2Nodes (40 partitions) the simulation is running fine.
I very appreciate your help.