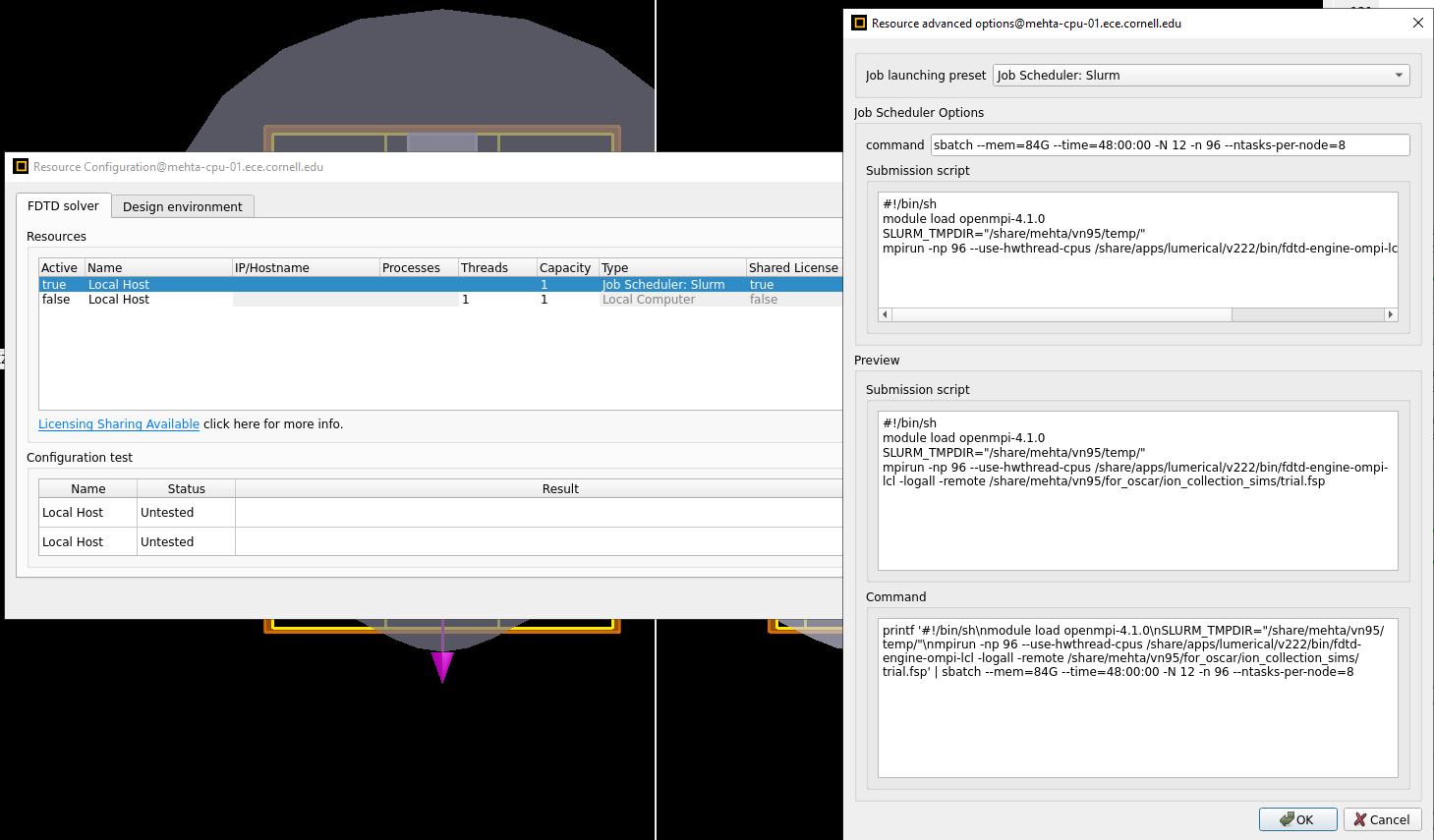
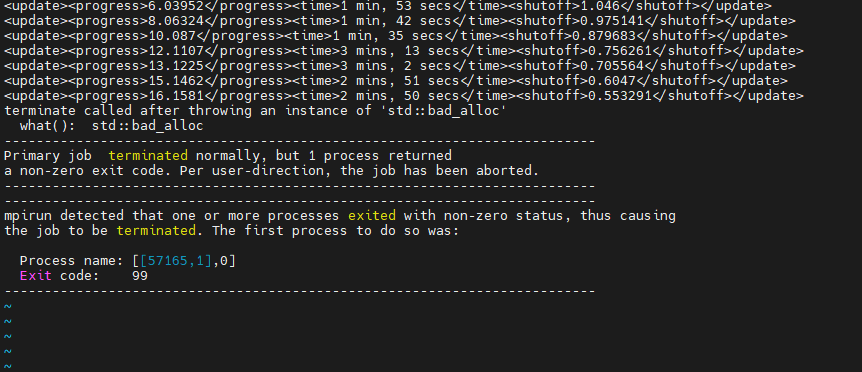
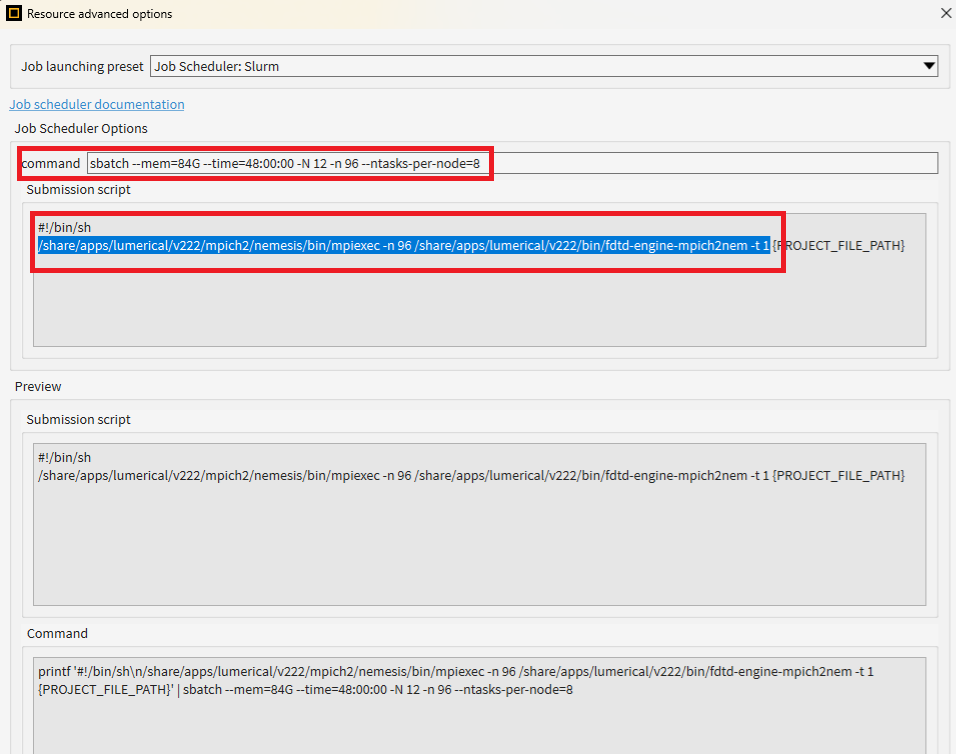
I run many parallel jobs on a cluster. Sometimes - for no apparent reason, the job crashes citing "std::bad_alloc", but no more information. The RAM is sufficient (I have verified this, I have allocated 10x the RAM that the requirements ask for - and have monitored that this is not reached via observing using htop). This crash doesnt happen if I use just a single core on a local computer resource setting. However it happens on parallel slurm jobs with multiple cores. I need to use multiple cores to speed up simulations.
This crash is not reproducible - it randomly happens, and if I run the same job again (same simulation with same resources in the resource manager), it sometimes runs and sometimes doesnt. Thus this leads me to believe that it doesn't have anything to do with RAM but is some other problem.
This issue is okay sometimes - where for many job submissions it does not crash, but sometimes it crashes quite often, which is not desirable - and it interrupts sweeps of simulations that I run.
This is with Lumerical version 2022 R2