Hello, I hope it's okay if I continue my questions in this thread. If not, I will repost them as a new topic, as this may also be of interest to other readers.
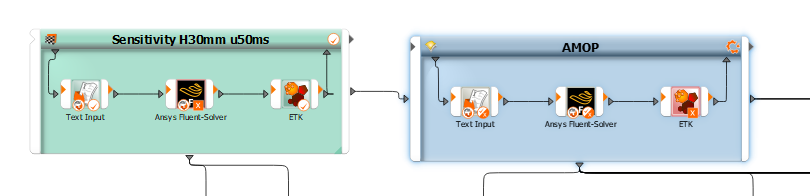
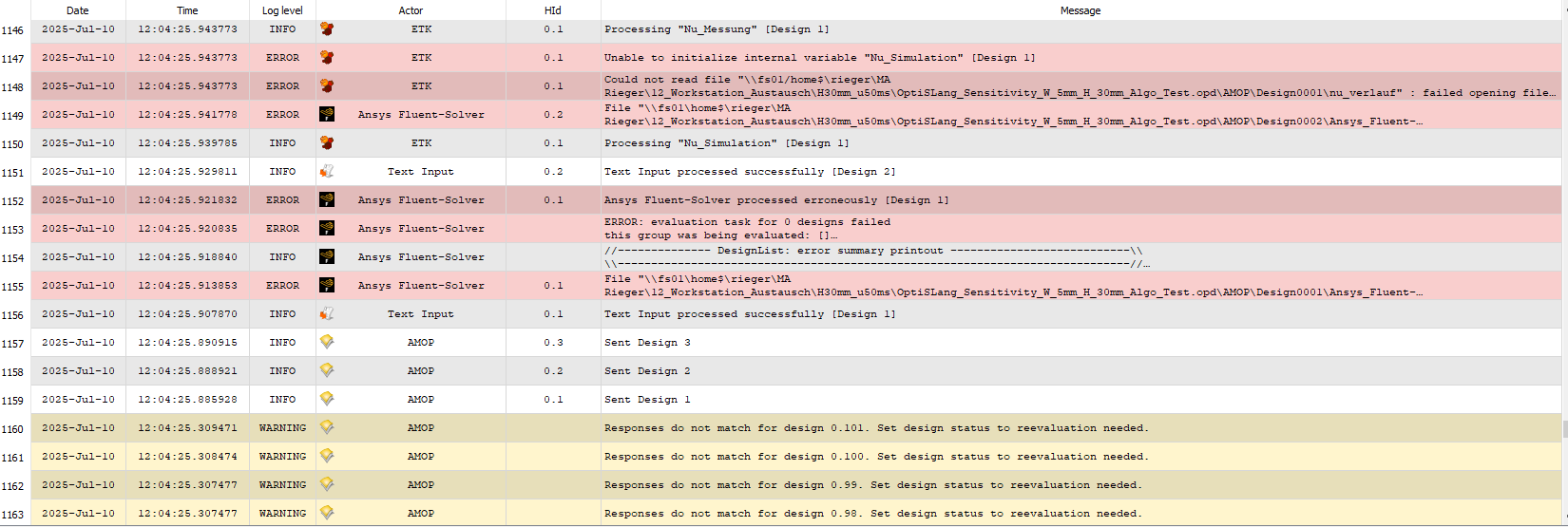
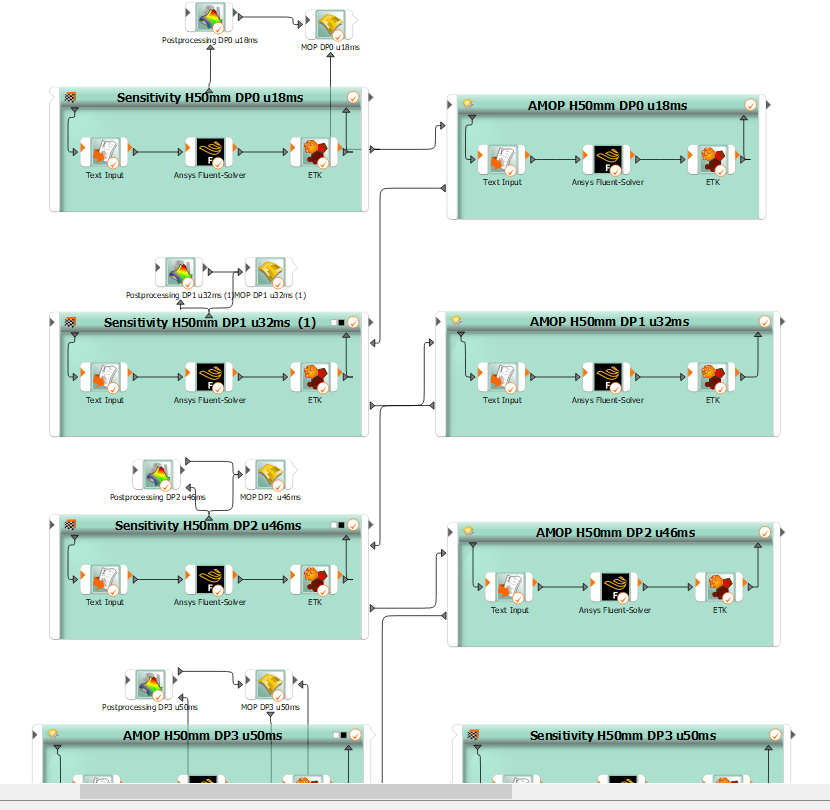
Thanks to your help, I have completed my sensitivity and AMOP calculations for the GEKO parameters. I now have a lot of data for GEKO parameters for discrete velocity u, that after AMOP or further optimisation, delivers a minimum error (MSE) compared to my experiment. As a small reminder, I want to use optiSlang to minimise the error of Nusselt curves between simulation and experiment.
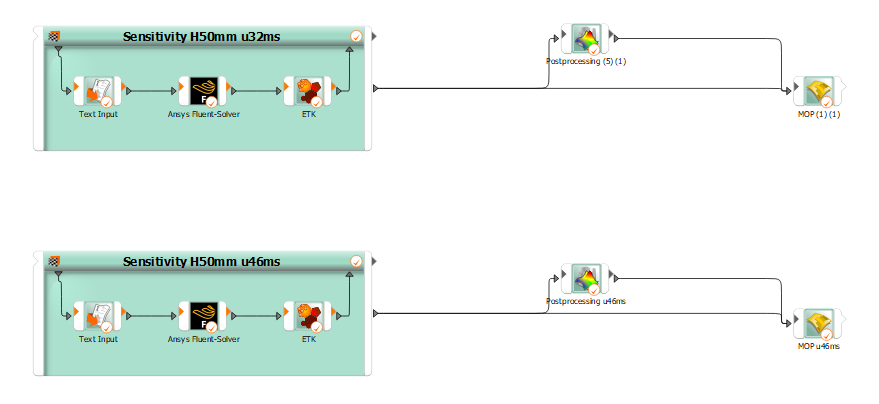
However, I am now wondering whether it is possible to combine the individual (AMOP)-metamodels that I have for each velocity into a single overall metamodel. In principle, I am looking for f(C_SEP, C_NW, ... , u) -> min(MSE) but do not know how this would be possible using OptiSLang. I hope this would allow one to obtain statements about an optimal parameter set for any velocity u from the combined metamodel.
Is there any further information/tutorials for this, or a helpful answer? Thank you in advance.
Greetings
Jan-Henrik