Hi Zihan
For the first question let me give a little backgorund first. In distributed parallel solutions, the FEM domain is split into N domains at the element level if using N cpu cores. Then N instances of the solver process (here MAPDL) are used to solve and each solve process takes one of the smaller domains to solve. Each process has to communicate with the other processes that share nodes (FEM nodes, not compute cluster nodes). If the amount of communication gets to be more than the computation that the cpu core is doing, then too many CPU cores are being used. So for any model there will be a point where using more CPU cores will just slow down the solve.
In the mathematics of solving FEA equations we use degrees of freedom [DOF] instead of number of nodes/elements. Let's say this is a FEM with only solid structural elements with translational DOFs in X, Y and Z. Then the total number of DOFs is 3 * number of nodes.
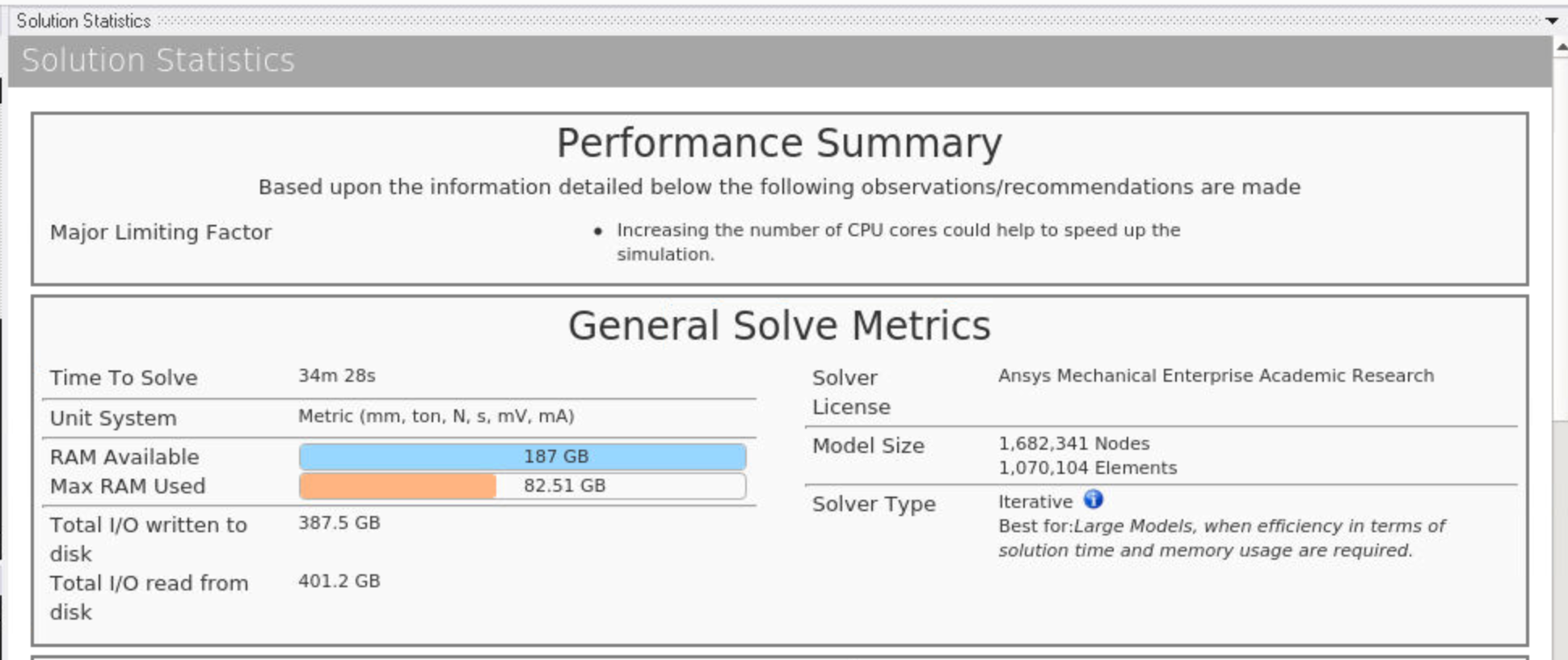
In order to know how many cpu cores to use we need to know the range of DOFs per cpu core where the cpu core is most efficient. When working with a new CPU that I've not tested before I assume something like 30,000 DOFs per cpu core and figure out how many cpus and compute nodes are needed from there. Ignoring any question on network communication speed between the compute nodes (for now).
So for your model I'd try 170 cpu cores or 7 compute nodes as a test. Then maybe try 6 and 8 compute nodes (fully used) to see how hardware responds to a little more and less dof's per cpu core. Depending on what happens you may then want to run other tests.
For now I'd not use the GPU as a solver accelerator. Since the GPU is helping all of the processes one GPU for 24 cpu cores is a bit much...I'd prefer to see 2 gpus for those 24 cores. Trying to keep to about 1 gpu per 12 or so cpu cores (and hence number of solver processes).
I'm also assuming the use of the sparse (direct) solver. If using the iterative solver then the dof's per cpu core will probably be different for that cluster.