Ansys Learning Forum › Forums › Discuss Simulation › Photonics › Lumerical cluster job crashes arbitrarily › Reply To: Lumerical cluster job crashes arbitrarily
April 20, 2024 at 5:43 pm
 Vighnesh Natarajan
Vighnesh Natarajan
Subscriber
Hello,
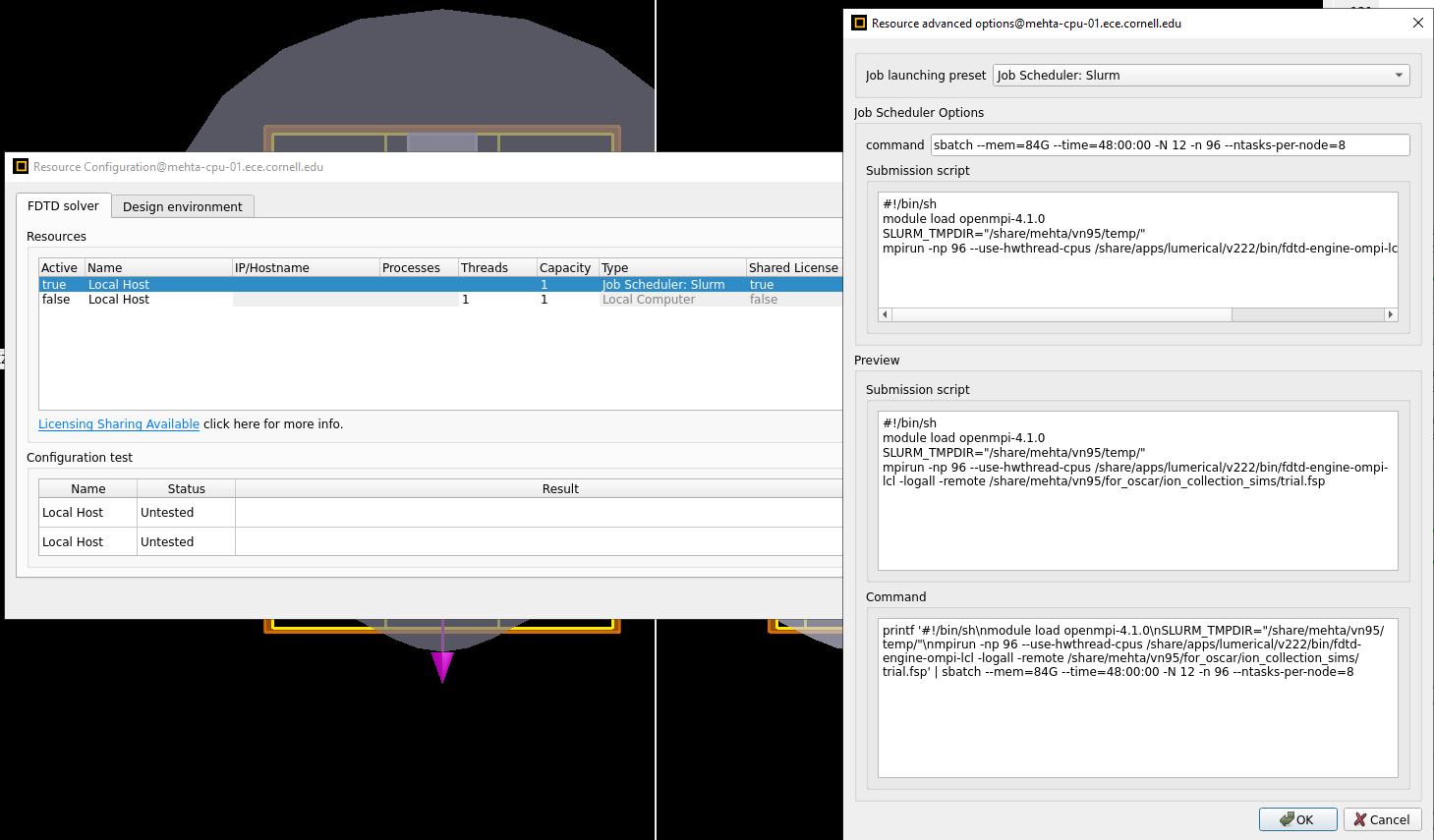
- I run the job from a GUI launched on a login node of the cluster. The resource manager in the GUI is set to use SLURM, which submits a batch job to the cluster
- Lumerical version is 2022 R2 (from the about page under help in the GUI)
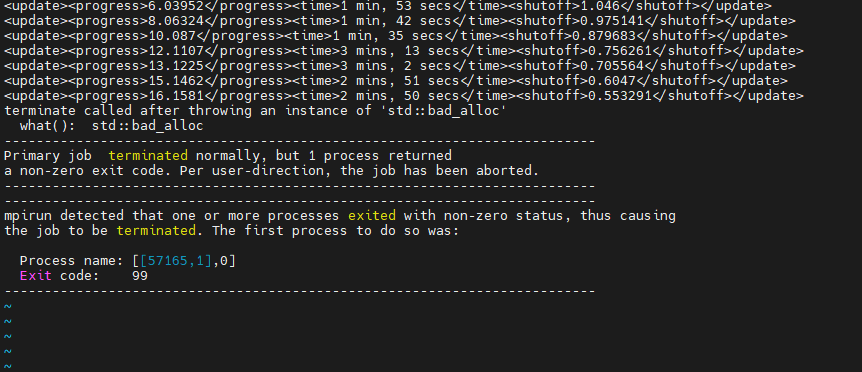
- I have attached an image below. Openmpi is already loaded, and has version 4.1.0. I have seen that KB. I think i am following the right guidelines - this script I use does run the job. The main mystery is occasionally the job crashes with error "std::bad_alloc", and as stated earlier, the job runs 90% of the time and fails 10%. The memory allocated for the job is atleast 10x what it would need (what i observe is described in more detail in the first message of this post) and the same job would not crash with a single core on local computer - just that it would take forever, so definitely not a RAM issue. But i'm unable to figure out why there is a bad_alloc and where it is happening. I have attached an image of the error thrown in the .out file of a job also below.