DTD算法非常适合并行运算,因此,从Lumerical公司成立的那一天起,FDTD Solutions计算引擎的核心部分就可以根据不同的计算机硬件并行运算。 另外,对于扫描和优化作业,需要仿真大量的文件,为了提高仿真效率,Lumerical公司也提供了相应的并行计算解决方案。根据仿真文件和所涉及的计算机硬件,有两种并行计算方法: 1:分布式并行运算 Distributed Parallel Simulation。 从Lumerical公司成立的那一天起,分布式并行运算就是一个缺省的选项,只要仿真需要,并且计算机有足够的核或者CPU,都可得以充分利用,此种并行运算是针对一个仿真文件和一台物理计算机(即一台个人电脑或者集群Cluster的节点)
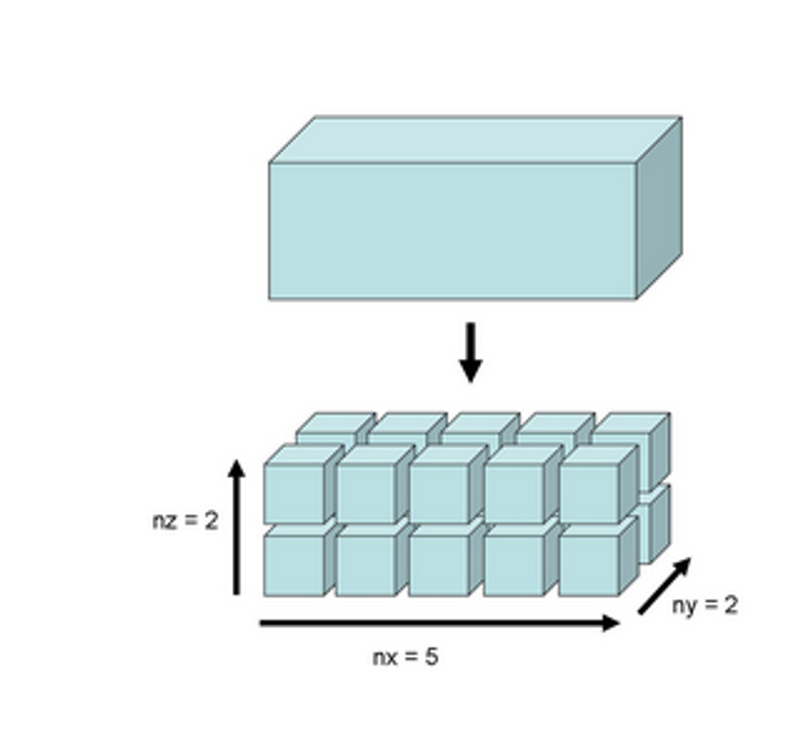
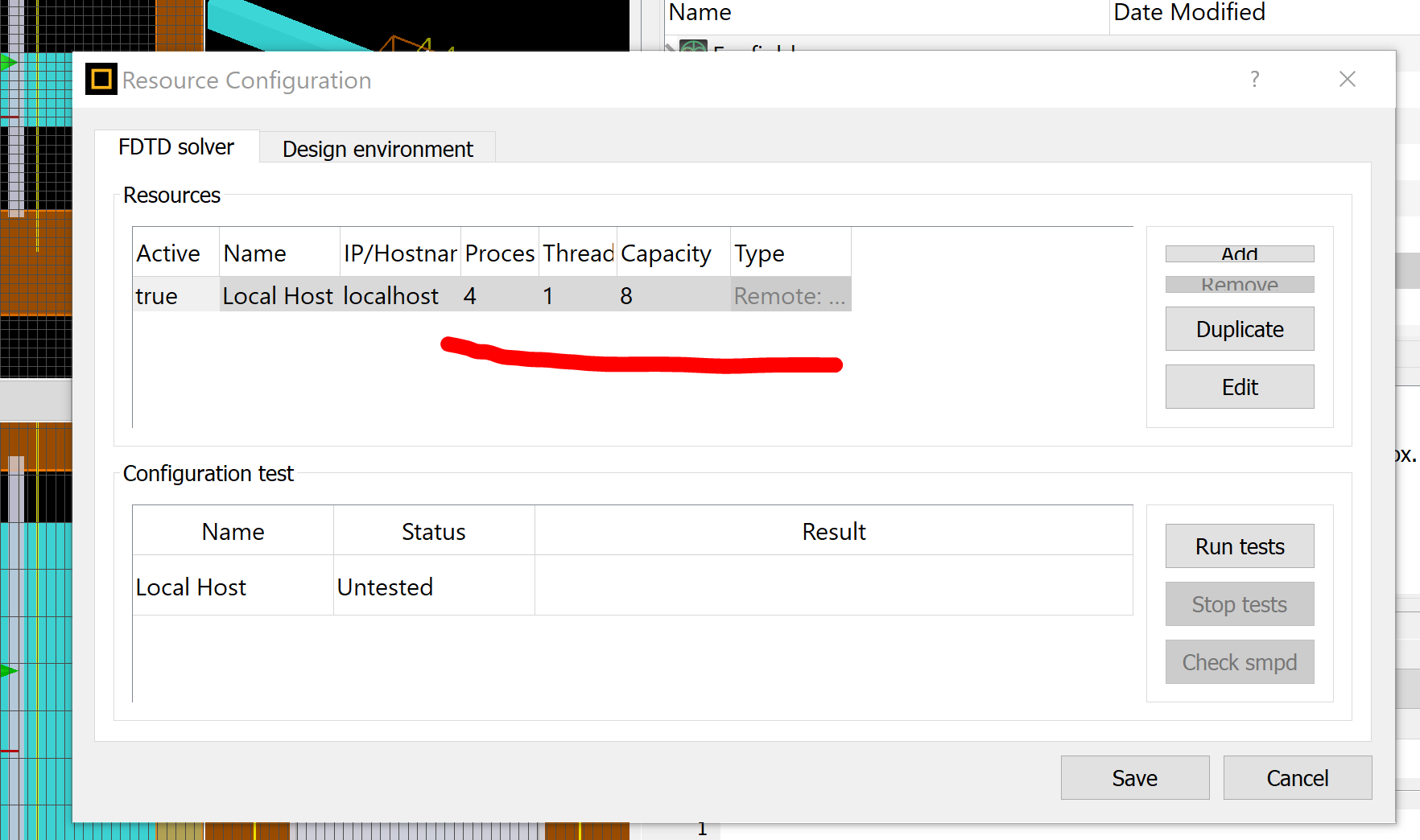
上方表示一个仿真文件的空间,下方表示它可以分解为5*2*2=20个小块,每个小块使用一个Process来计算。注意这里我们使用Process而不是核或者CPU,这是因为实际计算机它们三者之间的关系比较复杂。在缺省的情况下,只要用户在Resource那里设置Process个数,软件会自动地根据文件的大小选择最优的小块分布来并行运算。这种分布式并行运算不需要额外的License,只要能打开软件的GUI图形界面,就可以使用。
此外还有Thread线程设置,一般建议 Process*Thread不要超过Core数。
是否能加速仿真需要测试。当然,如果你有Engine License, 也可以不用图形界面而直接用命令行运行。
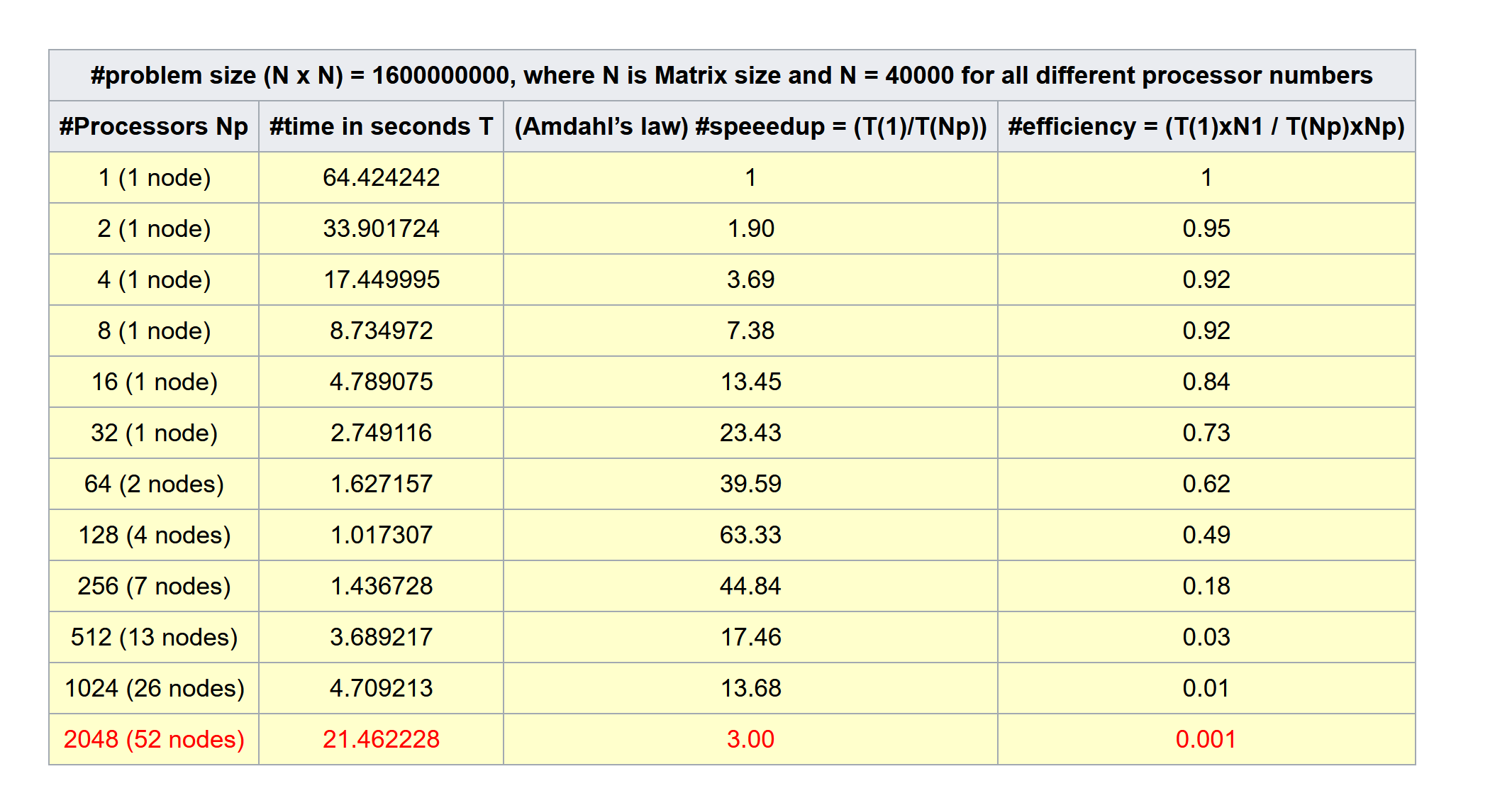
需要注意的是,由于在每个时间步长上每块需要与相邻的块交换数据(相当于边界条件),因此,并不是设置的Process个数越多越好,用户最好先行测试。具体每个Process最好有多少仿真量与计算机硬件有直接关系。这个问题在有高性能超级计算后比较突出,比如有用户的超级工作站是128GB,可以设置为128个Process,常常以为128能仿真更快,实际上很多小文件反而更慢。
软件本身支持多核并行、跨节点并行,支持不同 MPICH。
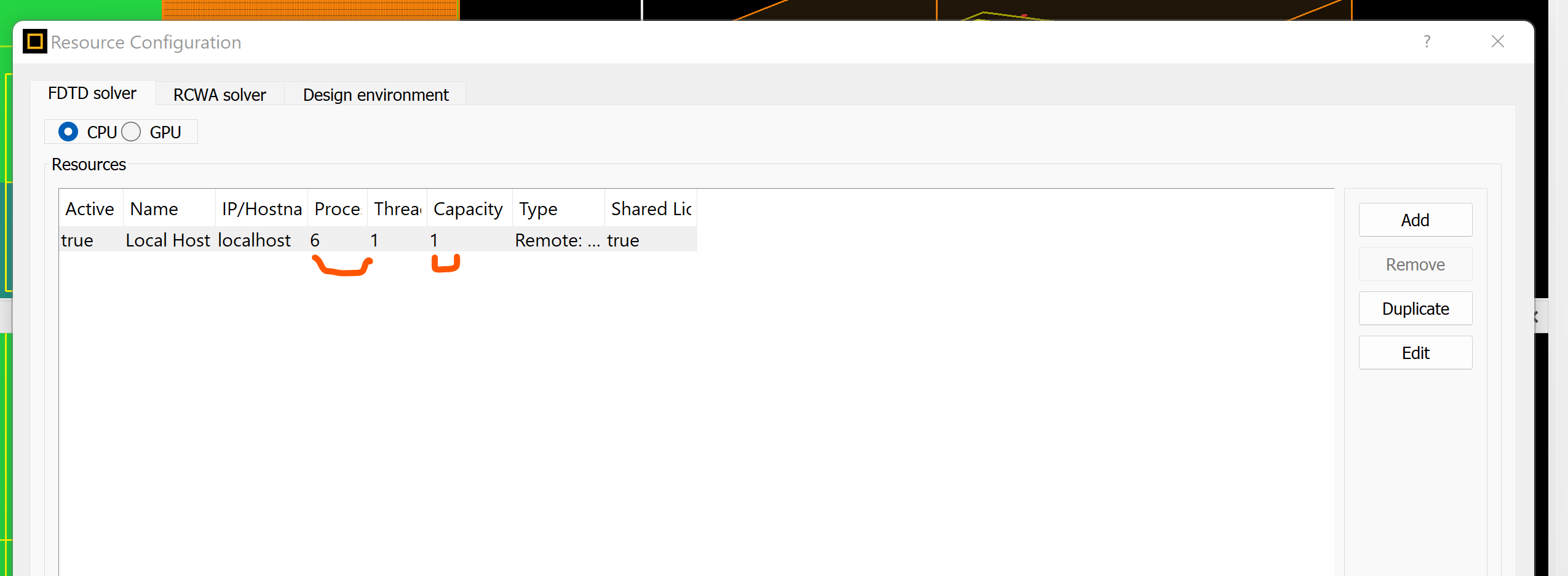
2:共发式并行运算Concurrent Parallel Simulation, 当用户需要参数扫描、优化时,需要大量的仿真,这种共发式并行运算就是针对这种情况设计的。此时,软件可以自动在不同的计算机上同时仿真不同的文件,而且每台计算仍然可以分布式并行运算,前提是,每台计算机上都必须有或者能链接Engine License,而且它们最好在同一个局域网内(即一个路由器下面)下图(图像丢失,遗憾)显示在Resource那里设置了5台机器,名字分别为local, node2,node3,node4 和 node5。其中local是当前打开仿真文件的当地机器; node2,node3,node4 和 node5是局域网内其它能够获取Licnese的机器,即这些机器或者本身安装了EngineLicense, 或者能够连接到安装Engine License的机器。此时,该用户共有一个FullLicense和4个Engine License。 如果你们计算机管理员并没有给计算机命名,也可以使用计算机的IP地址。如此,仿真将加快5倍。为了获得最好的仿真效果,我们建议参与仿真的计算机性能相当,否则某台性能差的计算机可能影响仿真效率,因为仅当所有文件仿真结束后,共发式并行运算才结束,并获取结果。如果文件的仿真量小,你的计算机性能也很好,你可以在同一台计算机上在仅有一个License实现这种共发式并行计算。
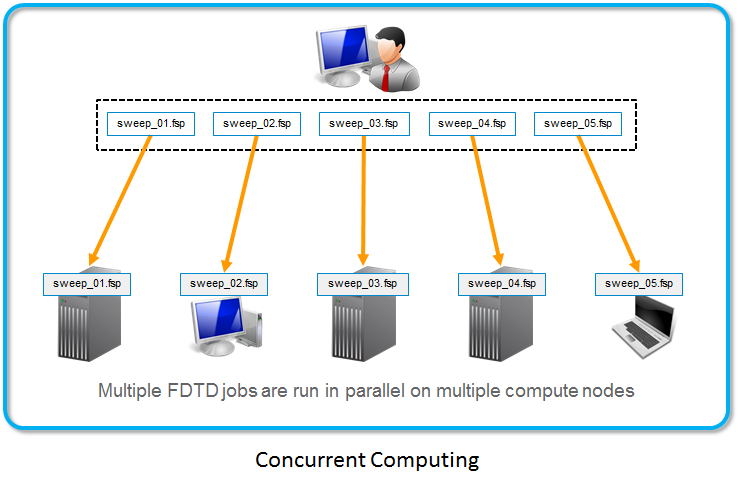
其设置同上面一样,只不过是你点复制就可以。
对于Concurrent 在这里的翻译,当时也比较犯难。考虑其共行性,是逻辑上同时发送和空间上的并行,再考虑与并行的区别,故翻译为共发。现在比较新的一种翻译是并发,但是由于我们已经使用共发,就一直沿用。
有关硬件配置的一般参考性意见参见这个帖子 :
Ansys Insight: FDTD 仿真硬件指标的一般性推荐